Chapter 8 Week7: 重回帰分析
8.3 重回帰分析とは
- 単回帰分析:変数が1つ
\[ \hat{y} = a + bx \]
- 重回帰分析:変数が2つ以上
\[ \hat{y} = a + {b_1}{x_1} + {b_2}{x_2} + {b_3}{x_3} \]
8.3.1 偏回帰係数
重回帰式における回帰係数:偏回帰係数(partial regression coefficient)
他の独立変数の影響を取り除いた残差変数によって、従属変数(もしくは従属変数から他の独立変数の影響を抜いた残差変数)を予測する場合の回帰係数のこと
平均化された 1 単位の比較
e.g., “When comparing two children whose mother have the same level of education, the child whose mother is x IQ points higher is predicted to have a test score is 6x higher, on average. (Gelman et al., 2020, pp. 134)
偏回帰係数は、単回帰のような、当該の独立変数と従属変数の関係を表していない。2つの独立変数の重回帰分析を例に挙げると、\(x_2\)の係数は、\(x_2\)から\(x_1\)の影響を除いた残差変数との関係を表す。従って、単なる\(x_2\)の影響ではなく、\(x_1\)から予測される\(x_2\)に対して、実際の\(x_2\)がどれだけ大きいかもしくは小さかったかを表す(\(x_1\)の値のわりにどの程度\(x_2\)の値が大きいか)。つまり、モデル内の他の変数との関係を踏まえて係数を解釈する必要がある。
変数間で単位が異なる場合、従属変数、独立変数をすべて標準化することで、標準化偏回帰係数(standardized partial regression coefficient)を算出し、変数間の影響力を比較する
(標準化)偏回帰係数は、従属変数と独立変数の因果関係を示すわけではないことに注意
8.4 重回帰分析を行う上での注意点
8.4.2 多重共線性(multicolinearity)
- 独立変数間の相関関係が高いと、偏回帰係数を正しく推定することができない
注 “Multicollinearity should not be confused with a raw strong correlation between predictors. What matters is the association between one or more predictor variables, conditional on the other variables in the model.”
(From: https://rdrr.io/cran/performance/man/check_collinearity.html)
多重共線性の問題がないかを確認するための3指標。分析前に閾値を設定し、論文内でも多重共線性の判断をどのようにするか明記しておくとよい
- 許容度(tolerance):値が 0.1以下で多重共線性があると判断される
- VIF(variance inflation factor): 論文でよく見る指標。許容度の逆数で、5-10以上だと多重共線性だと判断。
- 条件指数(condition index):15以上で強い多重共線性があると判断
8.4.3 外れ値
回帰直線は外れ値に大きく影響する
外れ値を調べる代表的な4指標
残差:各データの残差を標準値に変換し、± 2標準偏差もしくは ± 3以上の割合を調べる
クックの距離:データが回帰式全体に与える影響を示す指標。1以上で問題ありと判断される
てこ比:各ケースにおける複数の変数データが全体の平均からどの程度ずれているかの指標。平均てこ比の3倍以上の値を取る場合問題ありと判断される。
- 平均てこ比:独立変数の数 + 1 ÷ サンプルサイズ
マハラノビス距離:複数の独立変数における各データの平均と各ケースのデータの距離を示す指標。マハラノビスの表を参考に判断する(マハラノビスとてこ比を両方使う必要はない)。
8.5 投入方
- 重回帰分析の場合、独立変数を入れる順序でそれぞれの独立変数の有意性や偏回帰係数が変化する。
- どの方法を用いるのかは研究の目的によっても異なる。基本的に、分析の前に決めておく方がよい。
8.5.2 階層的投入法
- 階層的回帰分析とも言われる。理論や仮説に基づいて、独立変数を1つずつ投入していく。段階的にモデルに含めるため、各独立変数がどの程度決定係数の向上に影響を与えているか把握できる(強制投入法のあとに階層的投入法を行うなど)。
8.6 ハンズオンセッション
- 強制投入法、ステップワイズ法のやり方を確認
8.6.1 データの読み込み
#install.packages("readr")
library(readr)
dat <- read_csv("../stat_class_2025/sample_data/regression_data.csv")## Rows: 120 Columns: 8
## ── Column specification ───────────────────────────────────────────────────────
## Delimiter: ","
## dbl (8): ID, Placement, FirstT, MidT, LastT, EndT, Class, Course
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.- 必ず中身を確認。
## # A tibble: 6 × 8
## ID Placement FirstT MidT LastT EndT Class Course
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 15 35 84 85 90 1 2
## 2 2 29 17 72 76 85 1 2
## 3 3 17 45 64 54 70 1 1
## 4 4 77 59 42 48 34 0 0
## 5 5 54 31 20 10 13 0 0
## 6 6 51 18 52 34 15 1 18.6.2 基本統計量の算出
## vars n mean sd median trimmed mad min max range skew
## ID 1 120 60.50 34.79 60.5 60.50 44.48 1 120 119 0.00
## Placement 2 120 54.20 28.50 50.5 54.61 37.81 4 99 95 -0.02
## FirstT 3 120 54.19 24.00 54.0 54.22 31.13 10 99 89 0.02
## MidT 4 120 50.79 25.30 52.0 51.08 31.13 4 100 96 -0.09
## LastT 5 120 50.50 24.53 47.5 49.68 27.43 6 100 94 0.28
## EndT 6 120 52.50 25.18 53.0 52.74 31.13 6 98 92 -0.05
## Class 7 120 0.66 0.48 1.0 0.70 0.00 0 1 1 -0.66
## Course 8 120 0.97 0.81 1.0 0.96 1.48 0 2 2 0.06
## kurtosis se
## ID -1.23 3.18
## Placement -1.32 2.60
## FirstT -1.15 2.19
## MidT -1.12 2.31
## LastT -0.99 2.24
## EndT -1.13 2.30
## Class -1.58 0.04
## Course -1.48 0.078.6.3 データの図示
- 箱ひげ図
- 蜂群図

- 箱ひげ図 + 蜂群図
boxplot(dat[, 2:6], xlab = "Test", ylab = "Score", ylim = c(0, 100))
beeswarm(dat[, 2:6],
add = T #箱ひげ図の上に描画すると明示的に記す
)
8.6.4 相関関係の確認
- 高い相関関係を示す独立変数はない
## Call:psych::corr.test(x = dat[, 2:6])
## Correlation matrix
## Placement FirstT MidT LastT EndT
## Placement 1.00 0.02 -0.36 -0.09 -0.30
## FirstT 0.02 1.00 0.26 0.08 0.37
## MidT -0.36 0.26 1.00 0.43 0.85
## LastT -0.09 0.08 0.43 1.00 0.53
## EndT -0.30 0.37 0.85 0.53 1.00
## Sample Size
## [1] 120
## Probability values (Entries above the diagonal are adjusted for multiple tests.)
## Placement FirstT MidT LastT EndT
## Placement 0.00 0.99 0.00 0.99 0
## FirstT 0.80 0.00 0.02 0.99 0
## MidT 0.00 0.00 0.00 0.00 0
## LastT 0.33 0.40 0.00 0.00 0
## EndT 0.00 0.00 0.00 0.00 0
##
## To see confidence intervals of the correlations, print with the short=FALSE option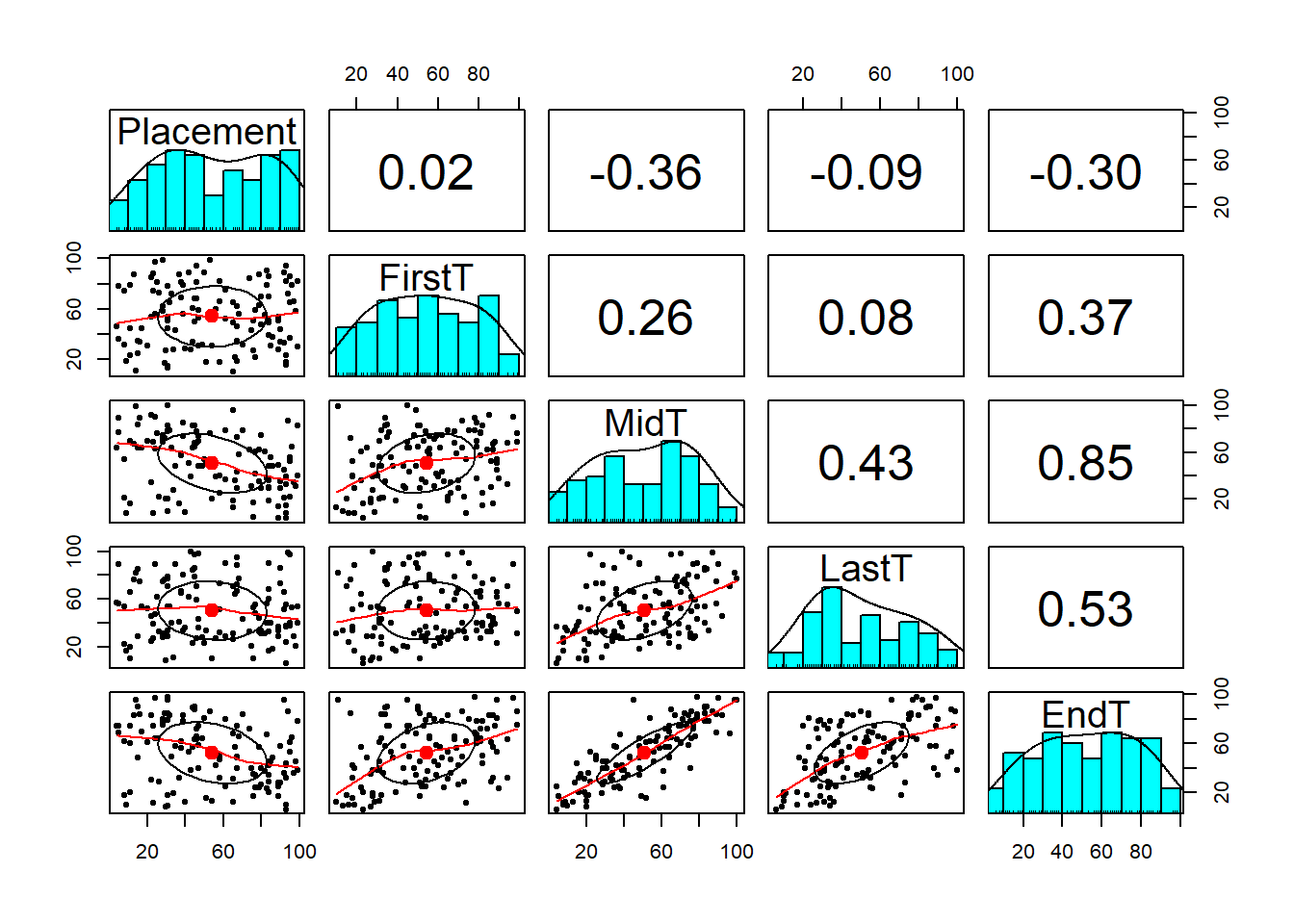
8.6.5 重回帰分析の実施(強制投入法)
lm()関数を使用する。重回帰分析の結果を
output_forcedという変数に格納する
summary()で結果を確認プレイスメントテストの係数が有意ではなく、年度末模試の予測に適さない可能性が示唆された。
Adjusted R-squaredの結果を確認すると、4つの独立変数で従属変数の77.6%を説明
##
## Call:
## lm(formula = EndT ~ Placement + FirstT + MidT + LastT, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -29.999 -6.532 0.373 7.884 39.006
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.11492 4.42429 -0.478 0.63354
## Placement -0.03101 0.04154 -0.747 0.45684
## FirstT 0.18318 0.04749 3.857 0.00019 ***
## MidT 0.69883 0.05334 13.101 < 0.0000000000000002 ***
## LastT 0.21533 0.04960 4.341 0.0000306 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.91 on 115 degrees of freedom
## Multiple R-squared: 0.7839, Adjusted R-squared: 0.7764
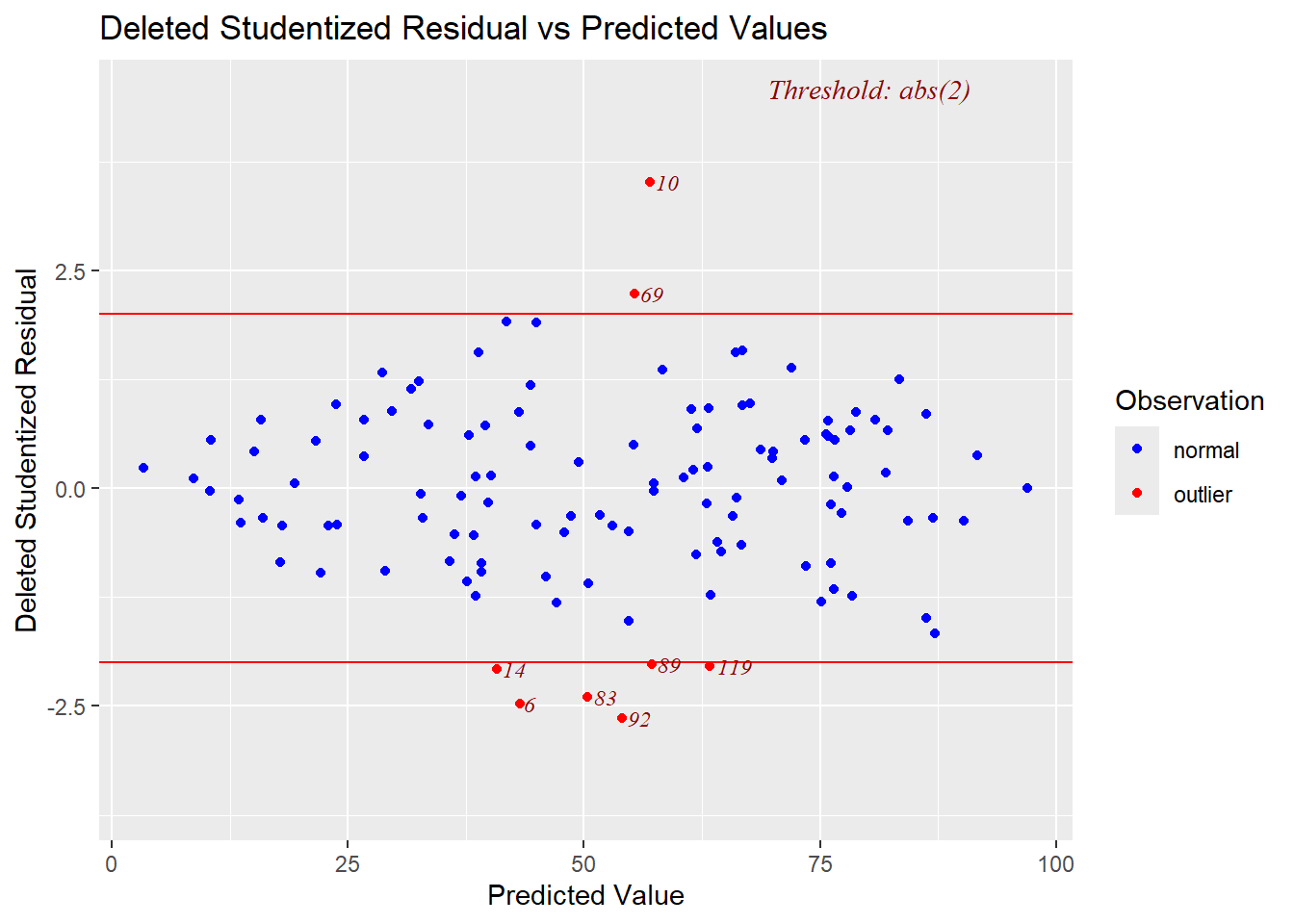
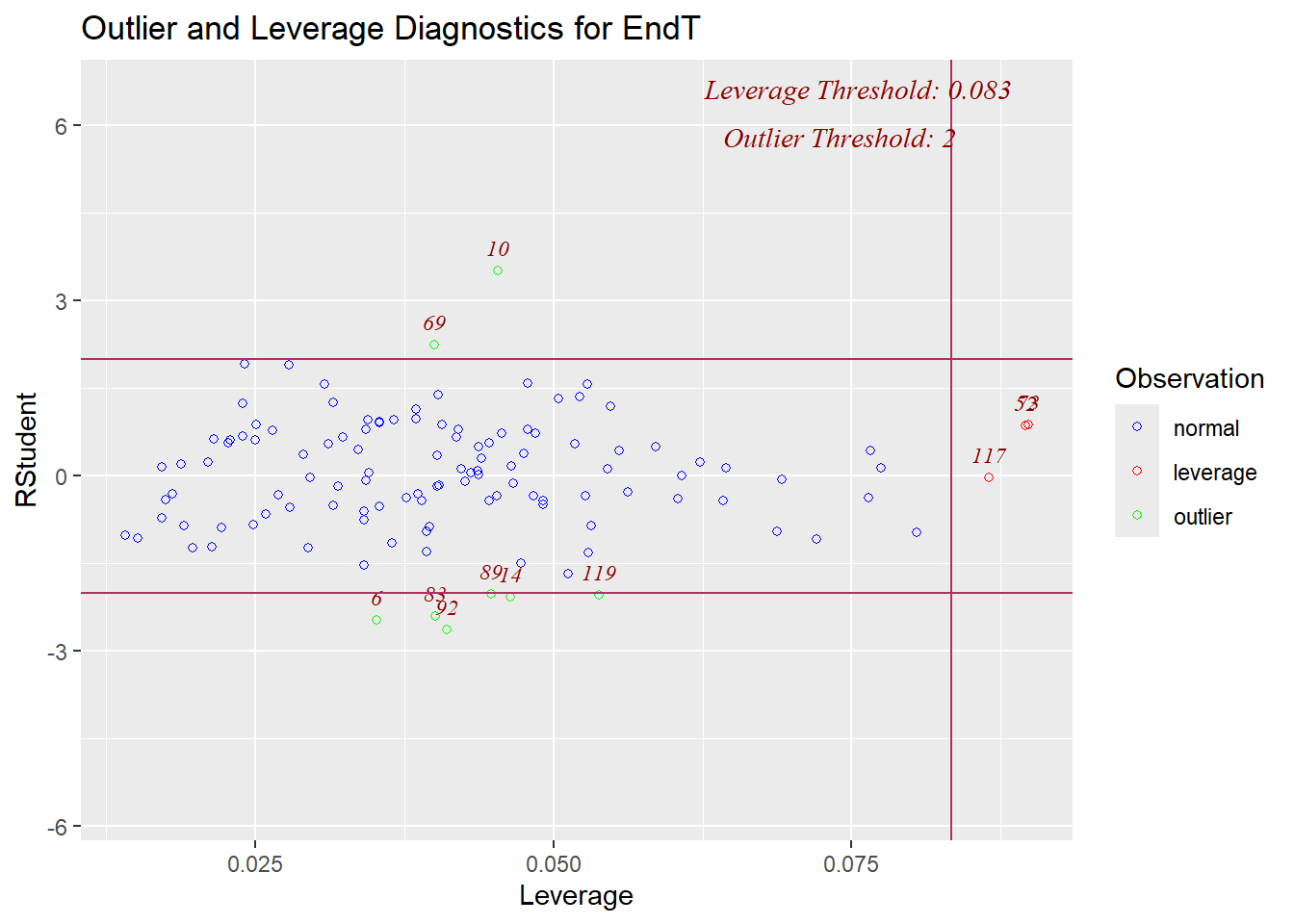
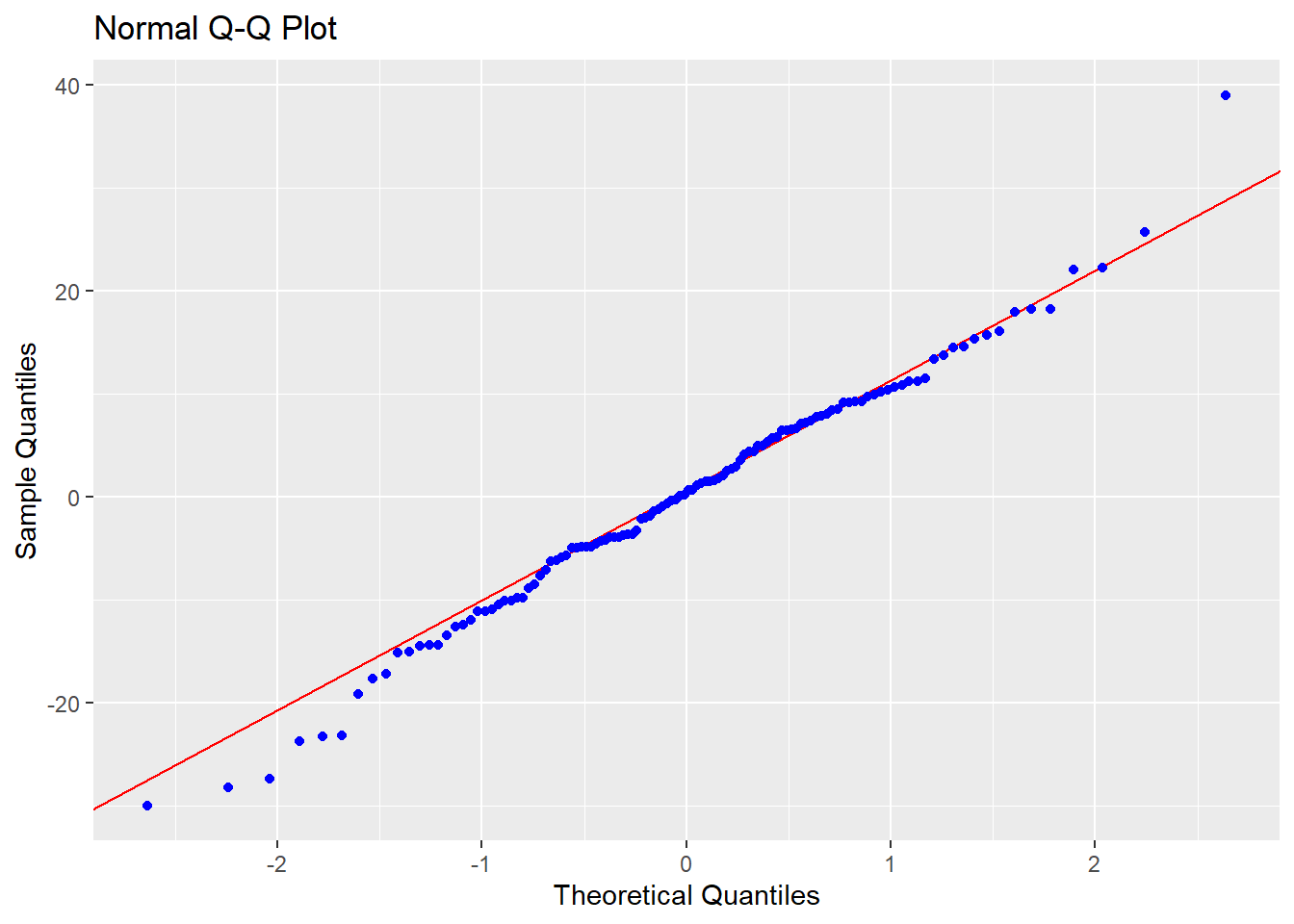
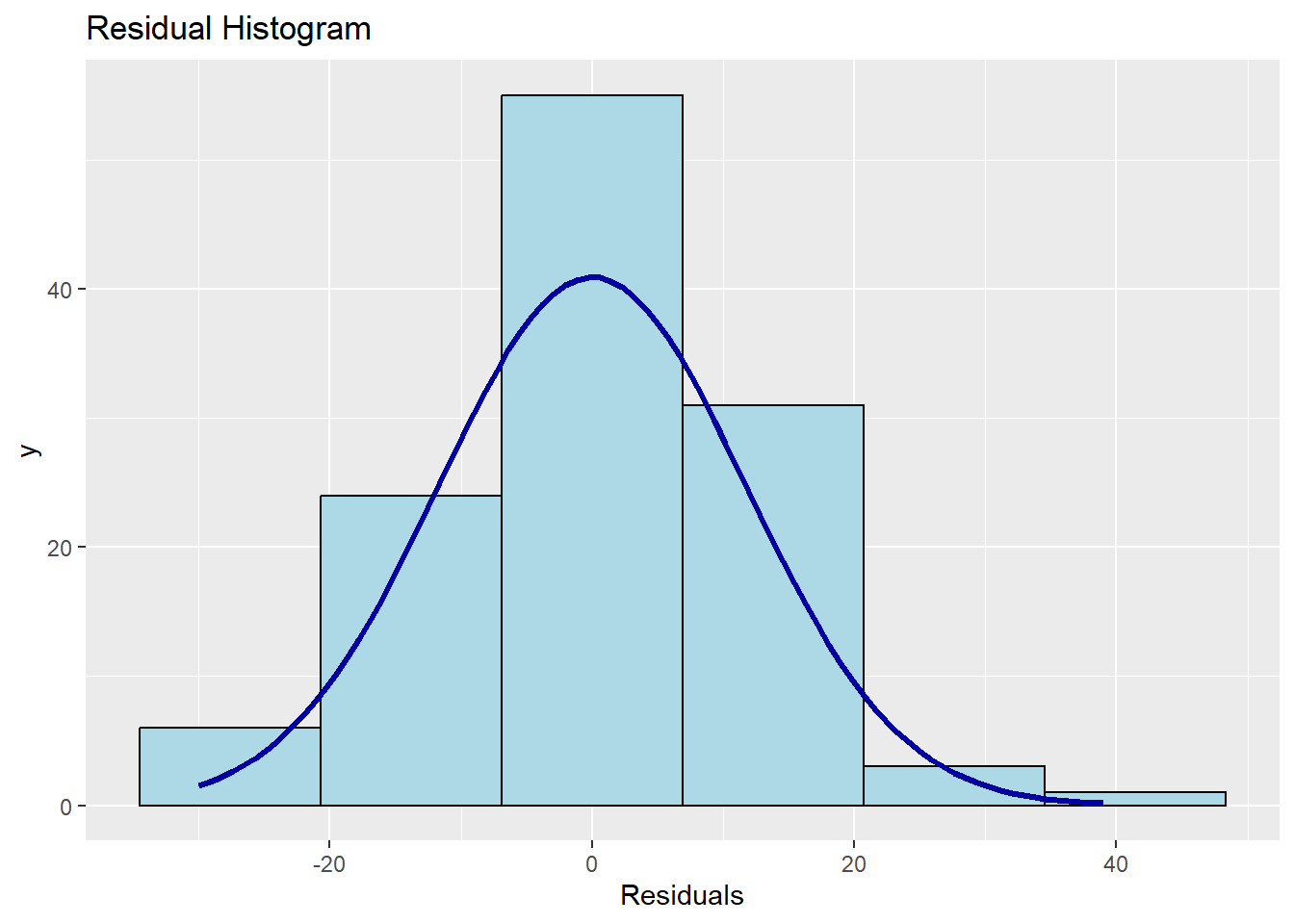
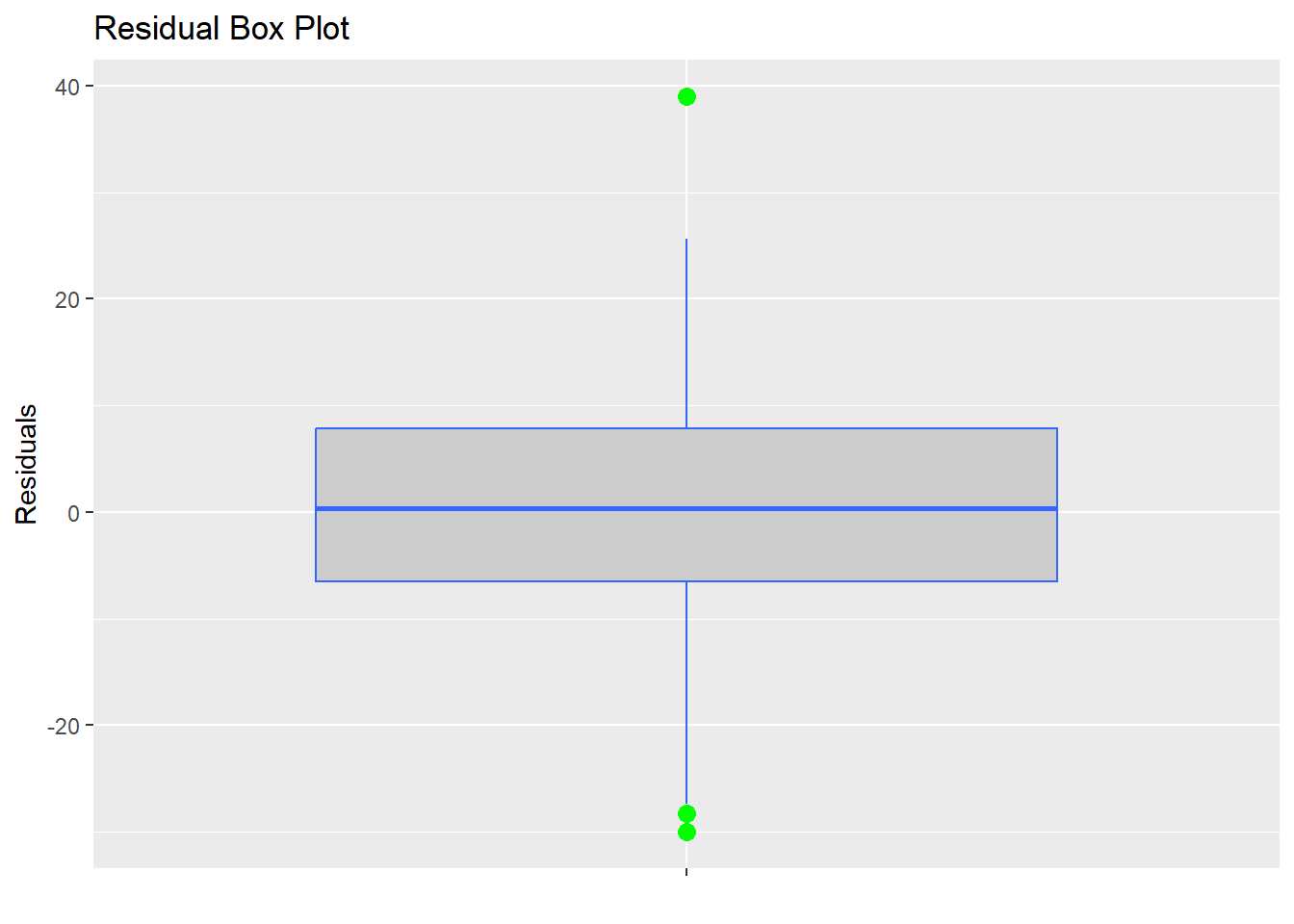
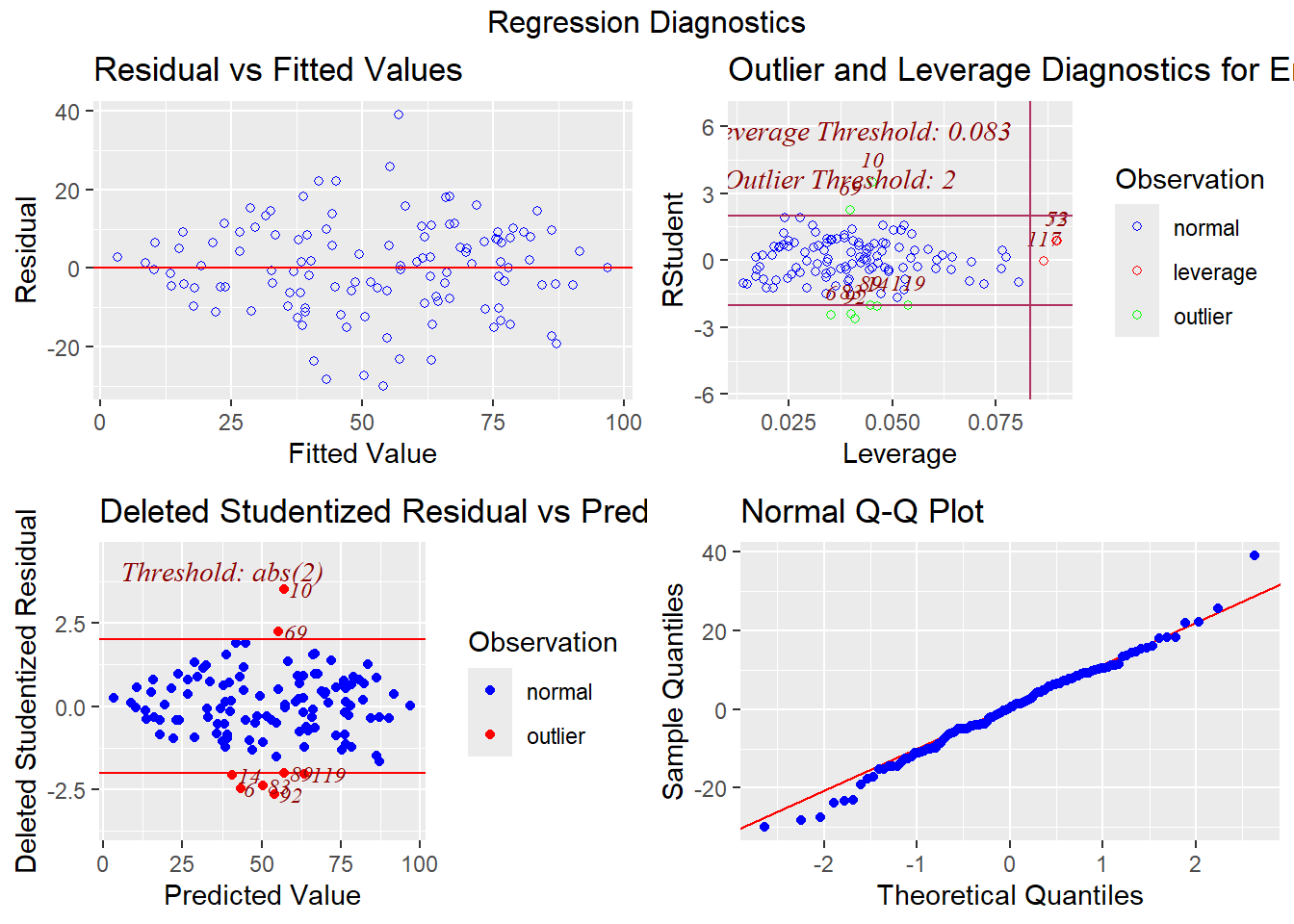
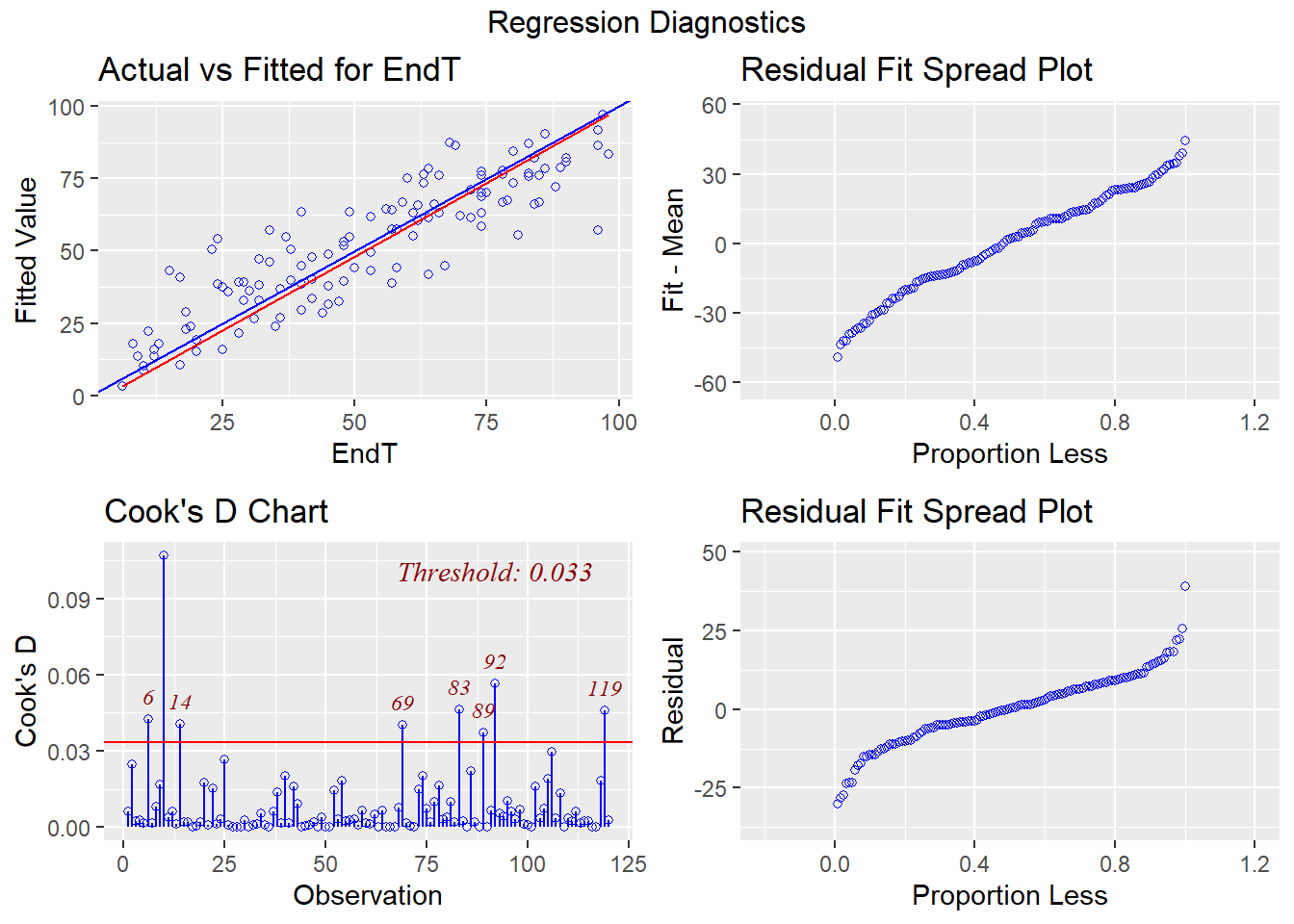
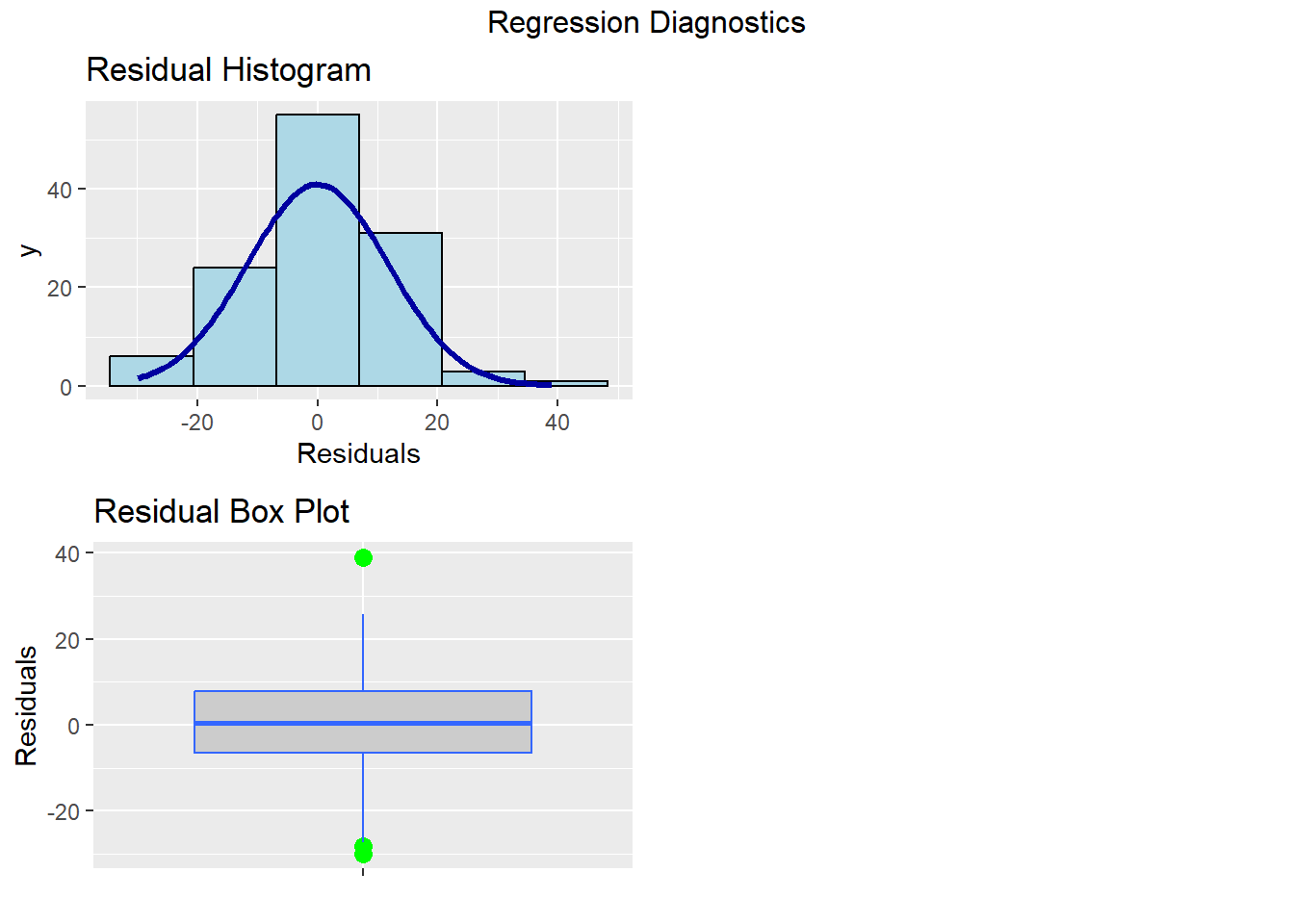
## F-statistic: 104.3 on 4 and 115 DF, p-value: < 0.000000000000000228.6.6 外れ値の診断
- 分析結果から
resid()関数で残差を算出し、その値をscale()関数で標準化
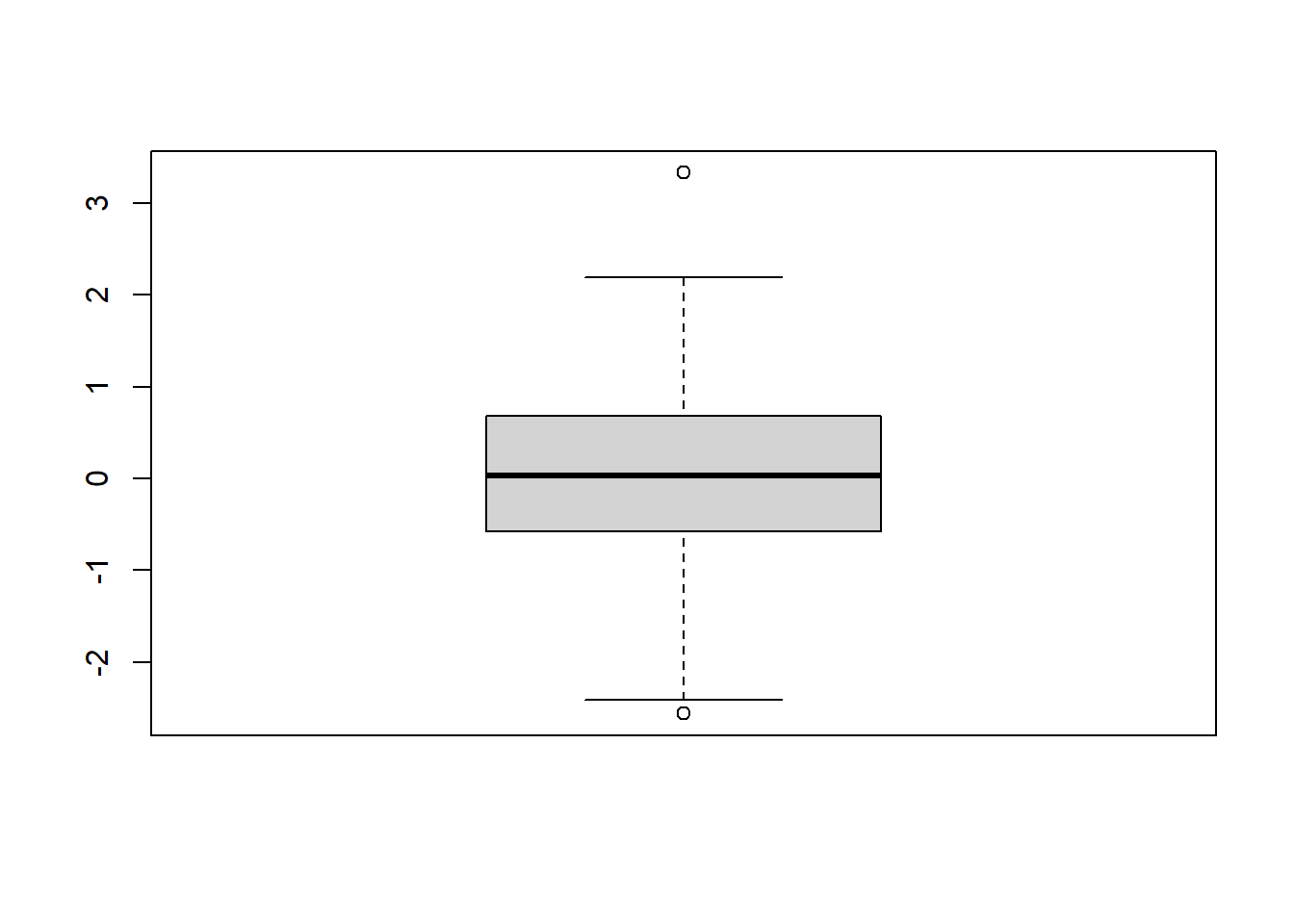
- 最大値、最小値の2つが外れ値の可能性あり
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 120 0 1 0.03 0.01 0.95 -2.56 3.33 5.9 -0.03 0.45 0.09olsrr関数を使うと、様々な図を一度に表示可能
## Warning: package 'olsrr' was built under R version 4.3.3##
## Attaching package: 'olsrr'## The following object is masked from 'package:datasets':
##
## rivers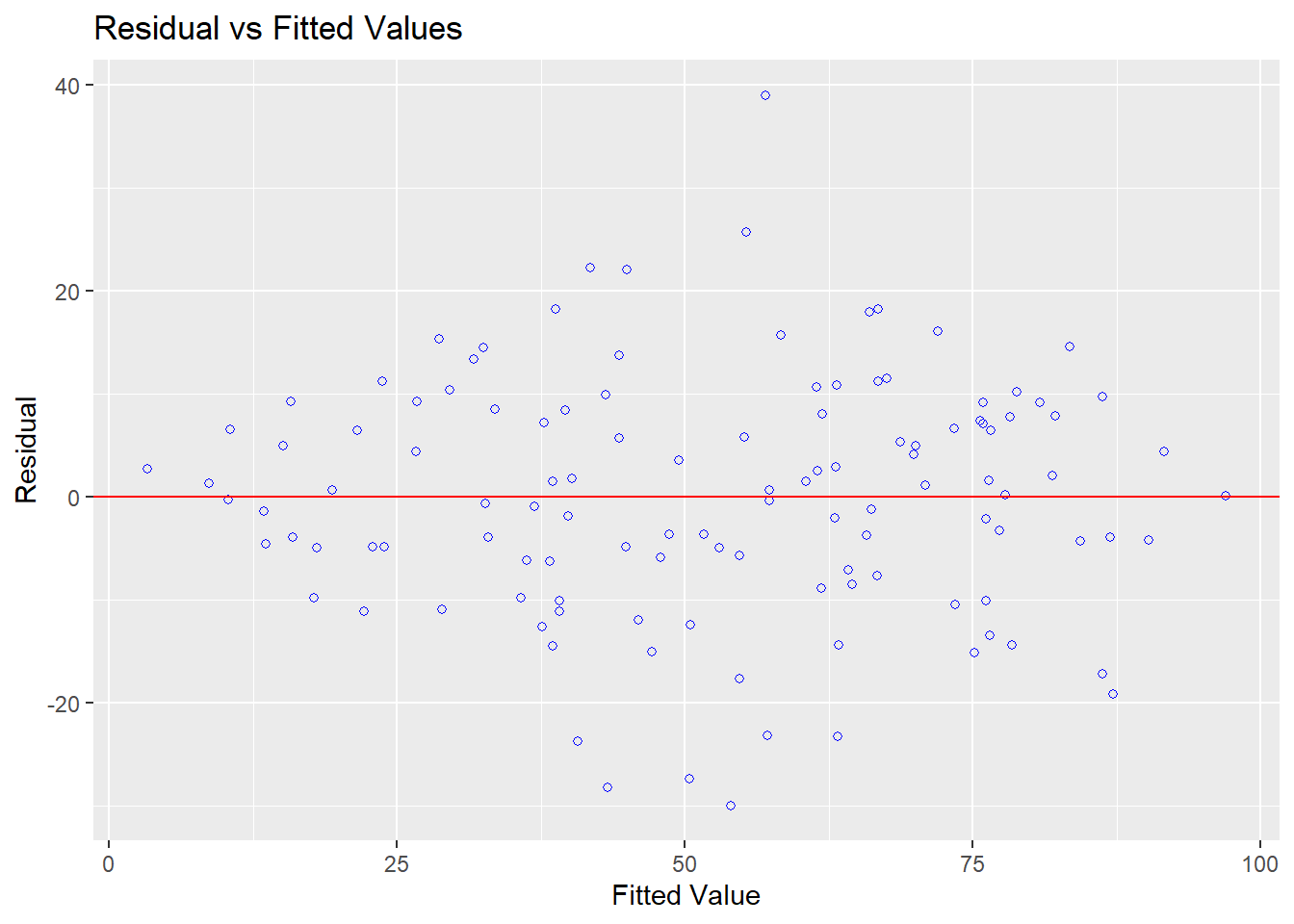
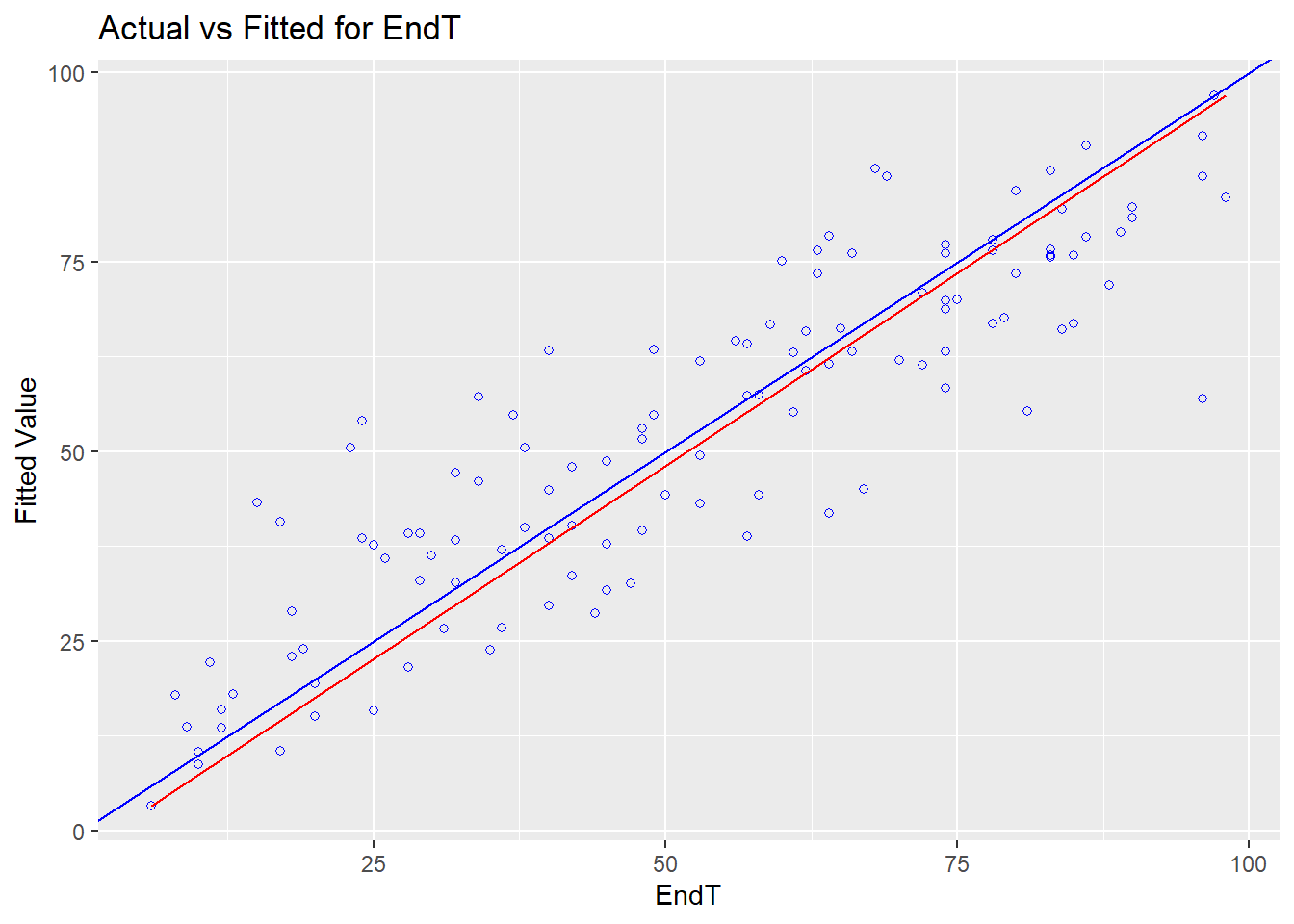
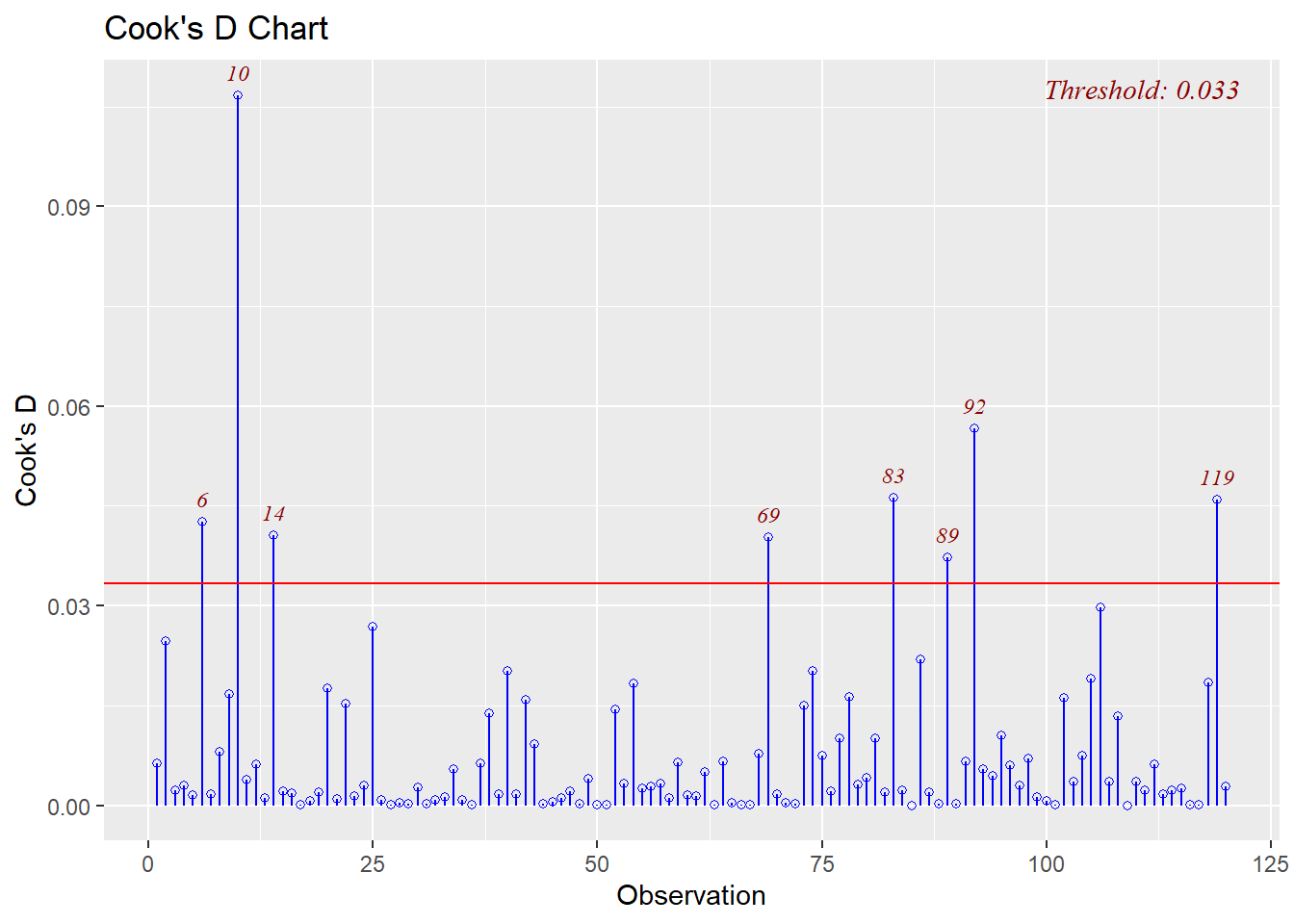
8.6.7 多重共線性の確認
多重共線性の問題はなさそう
- VIF: 5以上のものはない
- 許容度:0.1以下のものもない
- 条件指数(Condirion Index):全て15以下
## Tolerance and Variance Inflation Factor
## ---------------------------------------
## Variables Tolerance VIF
## 1 Placement 0.8502943 1.176063
## 2 FirstT 0.9170130 1.090497
## 3 MidT 0.6539385 1.529196
## 4 LastT 0.8049192 1.242361
##
##
## Eigenvalue and Condition Index
## ------------------------------
## Eigenvalue Condition Index intercept Placement FirstT
## 1 4.40535969 1.000000 0.00298802134 0.007522632 0.0068745860846
## 2 0.30501018 3.800437 0.00164204177 0.365472991 0.0000002735316
## 3 0.15650328 5.305532 0.00006369806 0.046463119 0.5262904224956
## 4 0.08687444 7.121061 0.01599506848 0.103299519 0.3709362786036
## 5 0.04625240 9.759409 0.97931117036 0.477241738 0.0958984392846
## MidT LastT
## 1 0.005788082 0.006945791
## 2 0.123931389 0.044863293
## 3 0.003523541 0.394117664
## 4 0.620787643 0.517410058
## 5 0.245969345 0.0366631948.6.8 重回帰分析の実施(ステップワイズ法)
step()関数を用いる。この関数では、AIC(Akaike’s Information Criterion)の値が最も低い(= 最も良いモデル)が選択される。AICが最も小さくなる変数をモデルから削除していった結果が出力される
-変数名:その変数を抜いたモデルの結果
none:すべての変数を含めたモデル
## Start: AIC=599.41
## EndT ~ Placement + FirstT + MidT + LastT
##
## Df Sum of Sq RSS AIC
## - Placement 1 79.0 16384 597.99
## <none> 16305 599.41
## - FirstT 1 2109.1 18414 612.00
## - LastT 1 2672.0 18977 615.62
## - MidT 1 24332.6 40637 706.99
##
## Step: AIC=597.99
## EndT ~ FirstT + MidT + LastT
##
## Df Sum of Sq RSS AIC
## <none> 16384 597.99
## - FirstT 1 2038.4 18422 610.06
## - LastT 1 2613.6 18997 613.75
## - MidT 1 29590.9 45974 719.80- Placementを抜いたモデルの結果
##
## Call:
## lm(formula = EndT ~ FirstT + MidT + LastT, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -30.995 -6.820 0.491 7.669 38.131
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -4.14790 3.48037 -1.192 0.235773
## FirstT 0.17853 0.04699 3.799 0.000233 ***
## MidT 0.71384 0.04932 14.474 < 0.0000000000000002 ***
## LastT 0.21220 0.04933 4.302 0.0000355 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.88 on 116 degrees of freedom
## Multiple R-squared: 0.7828, Adjusted R-squared: 0.7772
## F-statistic: 139.4 on 3 and 116 DF, p-value: < 0.000000000000000228.7 次週までの課題
8.8 参考文献
📚竹内・水本(編著)(2023)『外国語教育研究ハンドブック【増補版】―研究手法のより良い理解のために』松柏社
📚南風原(2002)『心理統計学の基礎―統合的理解のために』有斐閣アルマ
📚平井・岡・草薙(編著)(2022) 『教育・心理系研究のためのRによるデータ分析―論文作成への理論と実践集』東京図書
📚Gelman, Hill, & Vehtari (2020) Regression and Other Stories, Cambridge University Press
📄吉田・村井 (2021) 心理学的研究における重回帰分析の適用に関わる諸問題, 心理学研究, 92(3), 178-187.