Chapter 3 Week 2:要約統計量
3.4 記述統計学と推測統計学
3.5 データの尺度
4種類あり、比例、間隔、順序、名義の順に情報量が少なくなる
- 上の順序のデータを下の順位のデータに変換することはできるが、逆の変換はできない
3.5.2 間隔尺度(interval scale)
例:温度、テストの得点、偏差値、テストの平均点
メモリの間隔は同じ
ゼロは「何もない」ことを表さない
「足す」「引く」は可能。「かける」「わる」はできない。
3.6 「~とみなす」
テスト得点は厳密にいうと、間隔尺度とは言えない?
- 配点が1点と5点は5倍の違いがあるか?
- 0点は能力が全くないと言えるか?
しかしテスト得点を統計分析したい場面が多く、統計分析は間隔尺度以上のデータを必要とする。
テスト得点の間隔を等間隔にする努力を怠らないのであれば間隔尺度として「みなそう」ということに現状はなっている(完全に合意されているわけではない)。
- 本講義ではテスト得点を間隔尺度として「みなす」
3.7 要約統計量
データを取ったらとりあえず要約をする。
そのままのデータ(e.g., 100人分の素点)を人間はなかなか理解できない。
集まったデータを目的合わせて要約をし、分かりやすく提示する。
大別して代表値と散布度があり、前者は大体の値、後者はばらつきを表すデータ
3.7.1 各統計量
3.7.1.1 代表値
平均値(mean)
平均値は沢山ある:算術平均、幾何平均、移動平均
本講義では平均は算術平均を指す
算出方法:すべての数を足し合わせて、データの数で割る
中央値(median)
小さい方から並べてちょうど真ん中にある値
- 奇数の時:1, 2, 3 => 中央値は2
- 偶数の時:1, 2, 3, 4 => 中央値は = 2.5
平均値は外れ値の影響を受けやすいが、逆に外れ値を考慮しやすい。この二つは異なる基準であるため、平均値と中央値の二つを算出して比較するとよい。
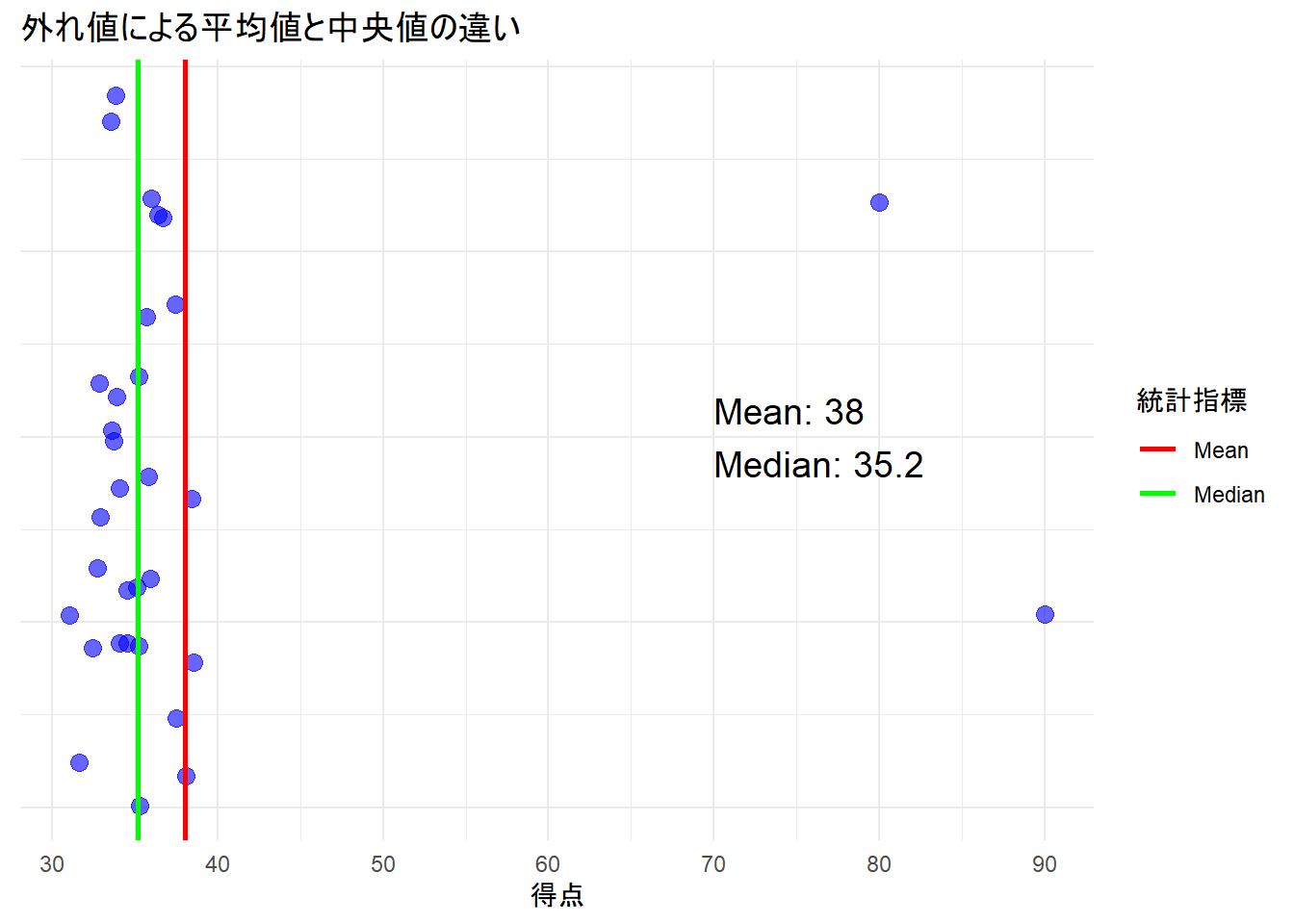
四分位(quantile)
小さい方から並べたデータを4分割する
- 第1四分位:データの25%
- 第2四分位:データの50%の個所 = 中央値
- 第3四分位:データの75%
最頻値(mode)
得られた数値をまとめ、同じ数字が何回出てくるか(度数: Frequency)を数える。その中で一番数が多い数字のこと。
名義尺度や順序尺度水準のデータはこの指標を使うとよい
例:以下は3人のアンケート結果です。それぞれ3つのポケモンを選んでいます。
| 回答者 | 1位 | 2位 | 3位 |
|---|---|---|---|
| Aさん | ピカチュウ | イーブイ | ゲンガー |
| Bさん | ピカチュウ | リザードン | ミュウ |
| Cさん | ピカチュウ | カビゴン | フシギバナ |
| ポケモン名 | 得票数 |
|---|---|
| ピカチュウ | 3 |
| イーブイ | 1 |
| ゲンガー | 1 |
| リザードン | 1 |
| ミュウ | 1 |
| カビゴン | 1 |
| フシギバナ | 1 |
- 最頻値は3でピカチュウの得票数が多かった。
3.7.1.2 散布度
分散(variance):σ2
- データが平均値の付近に密集している程度
- 値が大きいほどばらつきが大きい
\[\sigma^2=\frac{1}{N}\sum_{i=1}^N(x_i-\mu)^2\]
- N : データの数
- xi : データ一つ一つ
- u : 平均値
- 各データを平均値から引き、「平均値との差」という指標に変換( = 平均からの偏差)
- 全部足したいが、プラスとマイナスが混じっており、全部足すと0になる。
- 2乗し、全部プラスにする。
- 全部の偏差を足して、データの数で割る。
標準偏差(standard deviation):σ
- 分散のルートを取った値。分散は元のデータを2乗している。そのため単位が大きく解釈が困難なため。
- 値が大きいほどばらつきが大きい
\[\sqrt{σ^{2}}\]
平均、標準偏差などの要約だけではデータの全体像は見えにくい。下記の図のように、同じ平均、標準偏差(M = 50, SD = 10)でもデータの分布が異なることが分かる。このように、得られたデータの把握には、数値の要約だけでなく、可視化も重要となる。
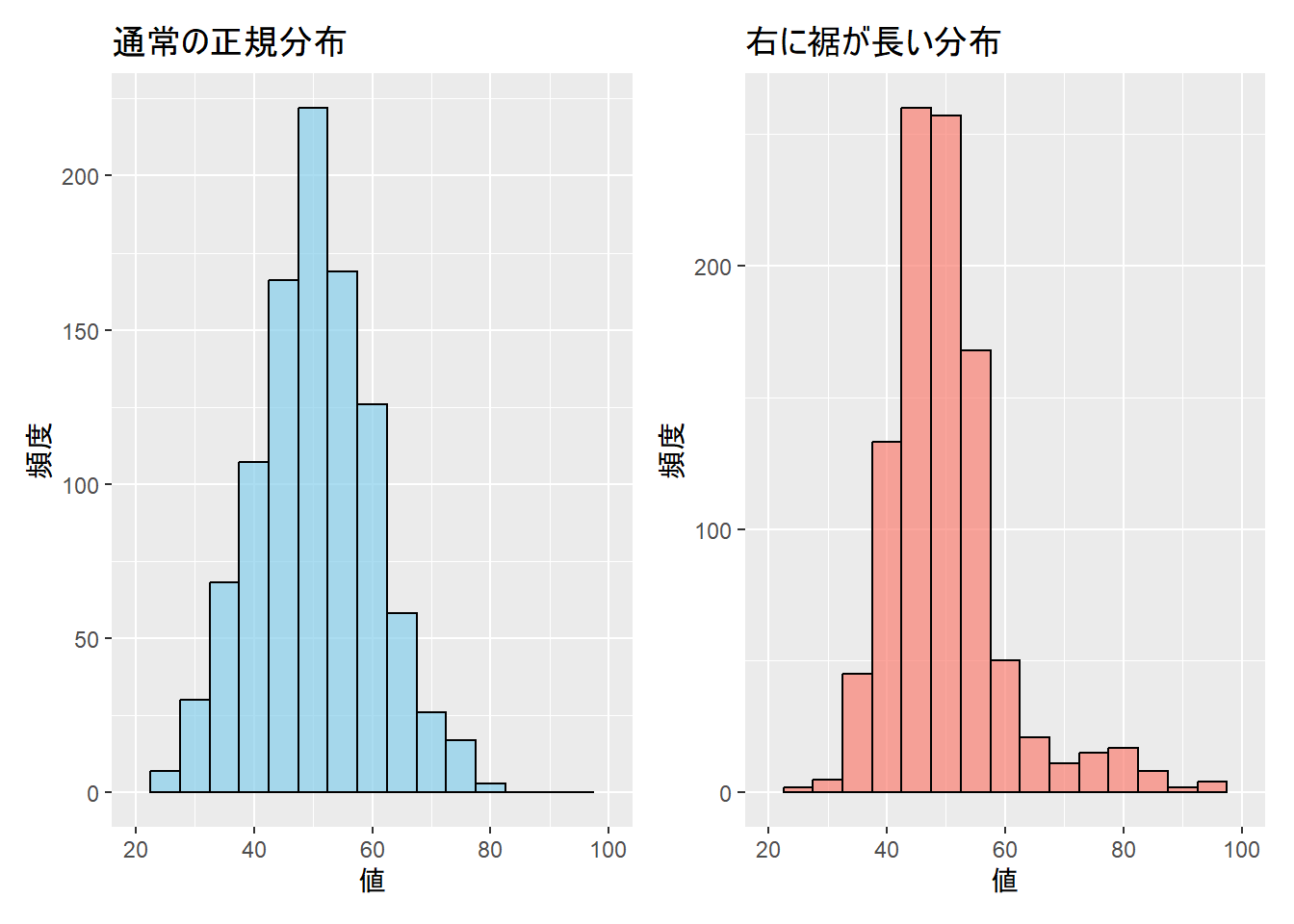
3.8 データの可視化
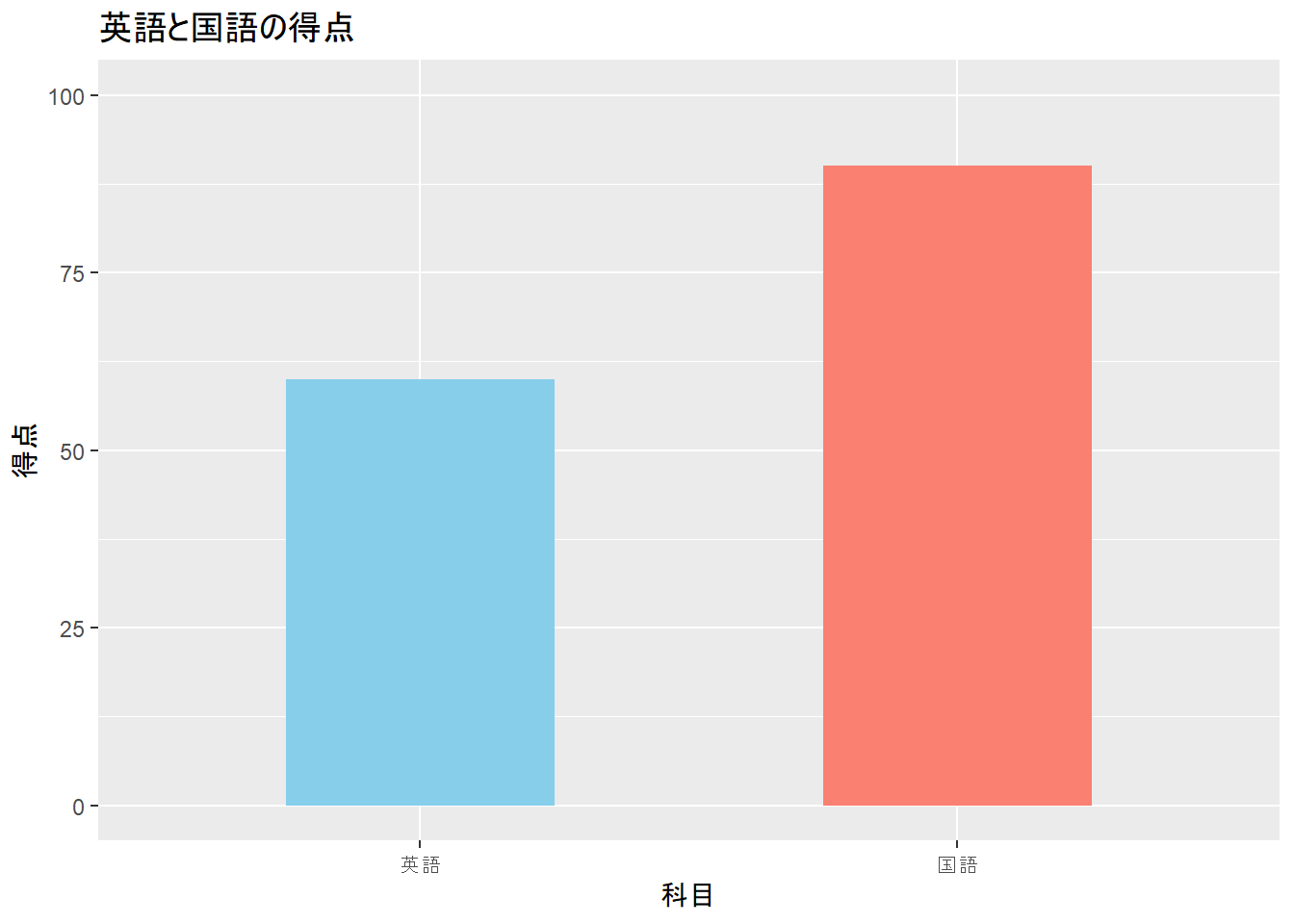
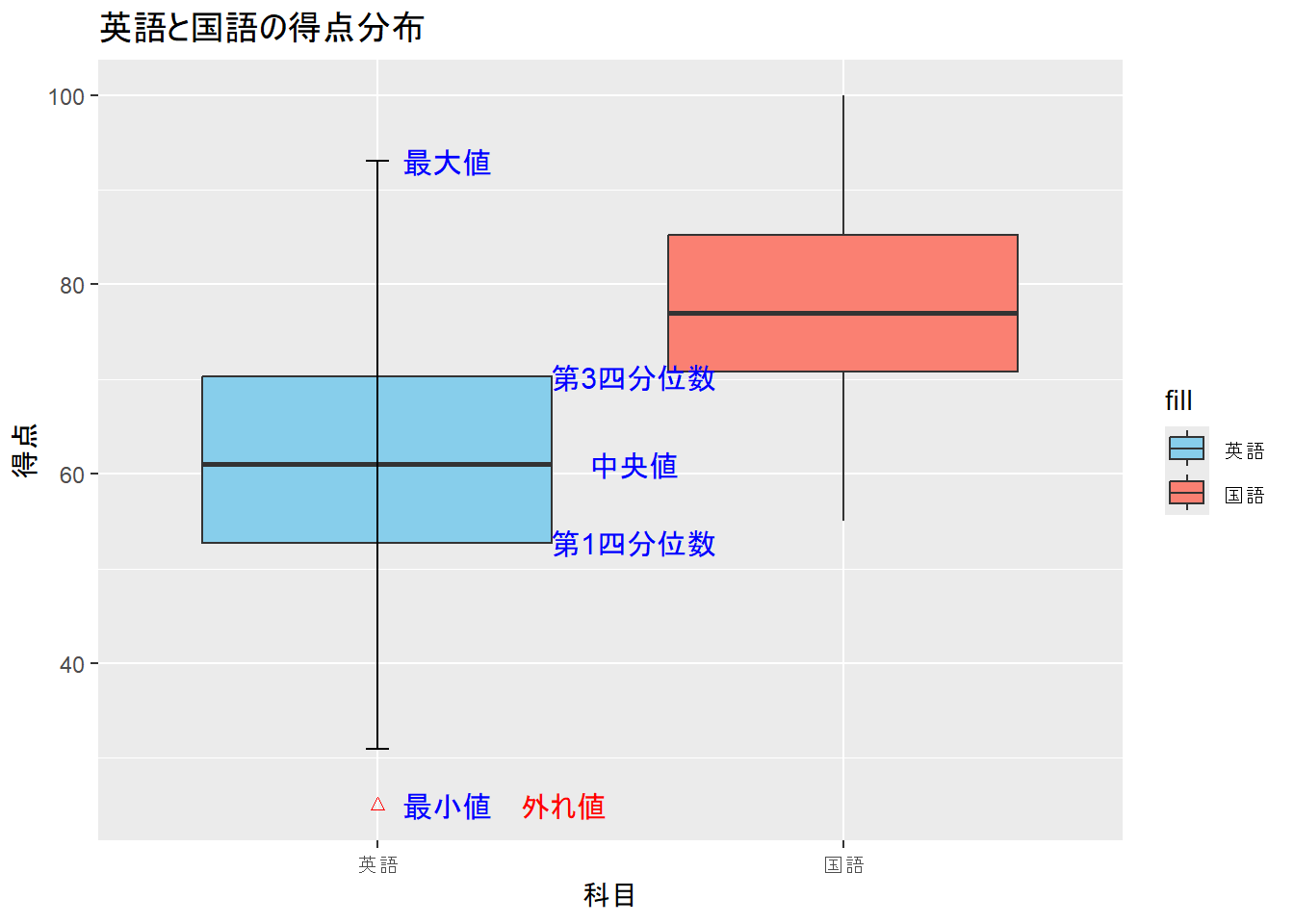
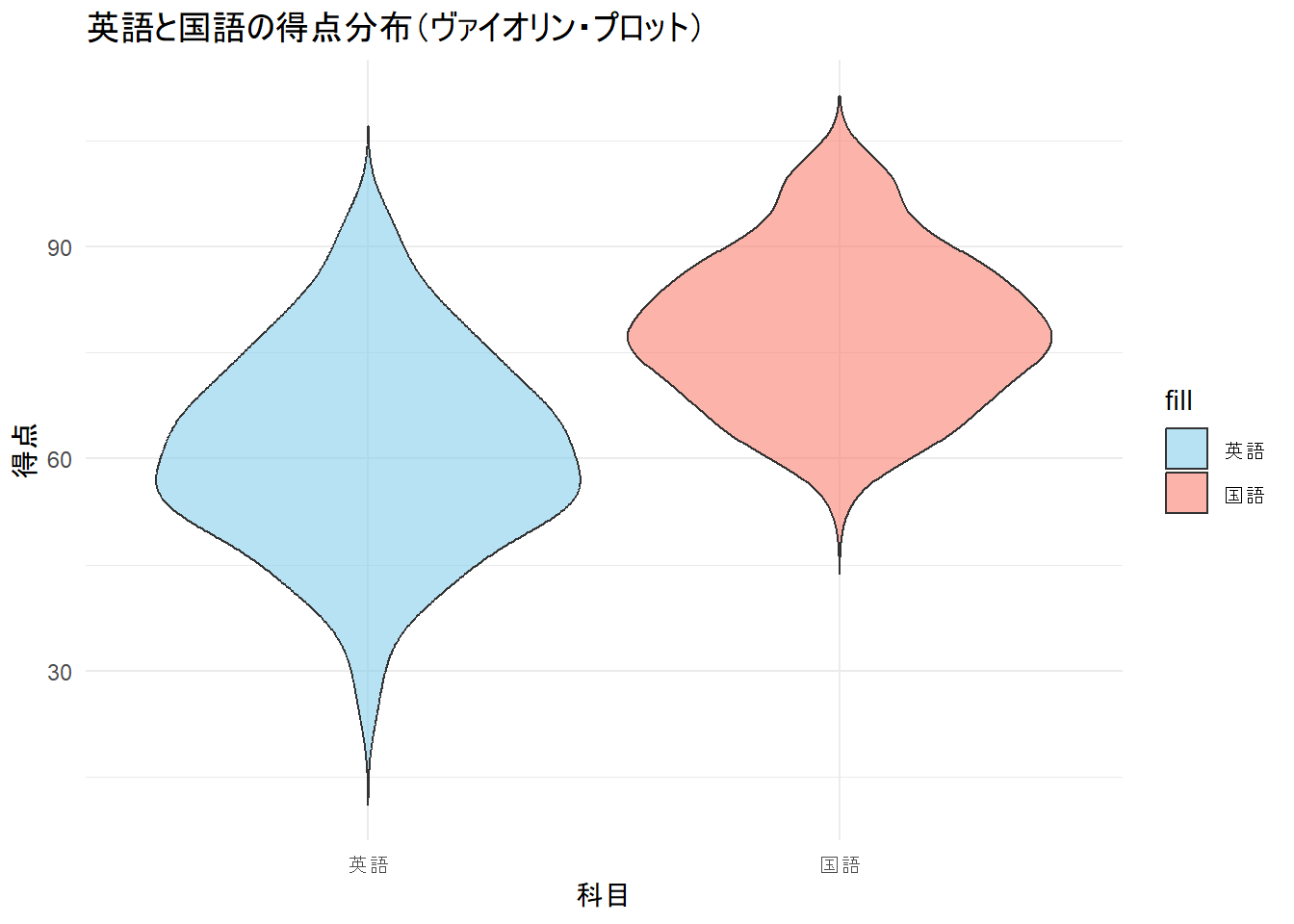
3.9 ハンズオンセッション
3.9.1 Rの基本用語
3.9.1.1 変数
どんなデータも格納できる箱。箱には必ず名前を付ける。名前は英数字のみを入れること。また、命名には規則がある。
- 名前の先頭に数字(e.g., 1hako)や記号(e.g., %hako)は使用できない
- 大文字と小文字は区別される(Hakoとhakoは別の変数として認識される)
プログラミングの世界では、以下の二つの命名の流儀がある。
- スネークケース🐍:変数の区切りを”_“で示す(e.g., snake_case)
- キャメルケース🐫:変数の区切りを大文字で示す(e.g., camelCase)
自由に箱(変数)に名前を付けてよいが、できるだけ自分の中で一貫したルールを持ち、第三者が見ても何が格納されているか分かりやすい名前を付けることを意識する。
変数に入れたデータは、[Environment]タブに表示される。
変数の中身が数値の場合、数値を足したりかけたりなど計算ができる。
- numという名前の変数に1から10の数字を入れ、それらを2倍した
## [1] 1 2 3 4 5 6 7 8 9 10## [1] 2 4 6 8 10 12 14 16 18 20- 変数の中身は上書きすることもできる
3.9.1.2 データの型
「いちたすに」と「1 + 2」はコンピュータにとっては別もの
- 実数型(numeric):数値全般(e.g., 10.4)
- 整数型(integer):整数のみ(e.g., 10)
- 文字列型(character):文字(e.g., “十”)。入力する際は
""や''で囲む - 論理型(logical):TRUEとFALSEからなる
- 因子型(factor):データに順番(数字を割り振る)
## int [1:4] 1 2 3 4## Factor w/ 4 levels "4","3","2","1": 4 3 2 13.9.1.3 関数
パッケージに含まれている、命令を実行するのに必要なもの。
data.frame()のような文字列とかっこの組み合わせ。かっこの中にデータを格納する。数学の関数とイメージしてもよい。例えば、Y = 2x という関数は、xを2倍する関数。入れたデータが2倍されて返ってくる。
使う際は呼び出す必要があり、Rのセッションが切れるまでは何回も呼び出す必要はない。Rに標準で備わっているものは呼び出す必要はない(base関数という)。
- 下の例では、
plot()関数で変数の中身を描画している
- 下の例では、
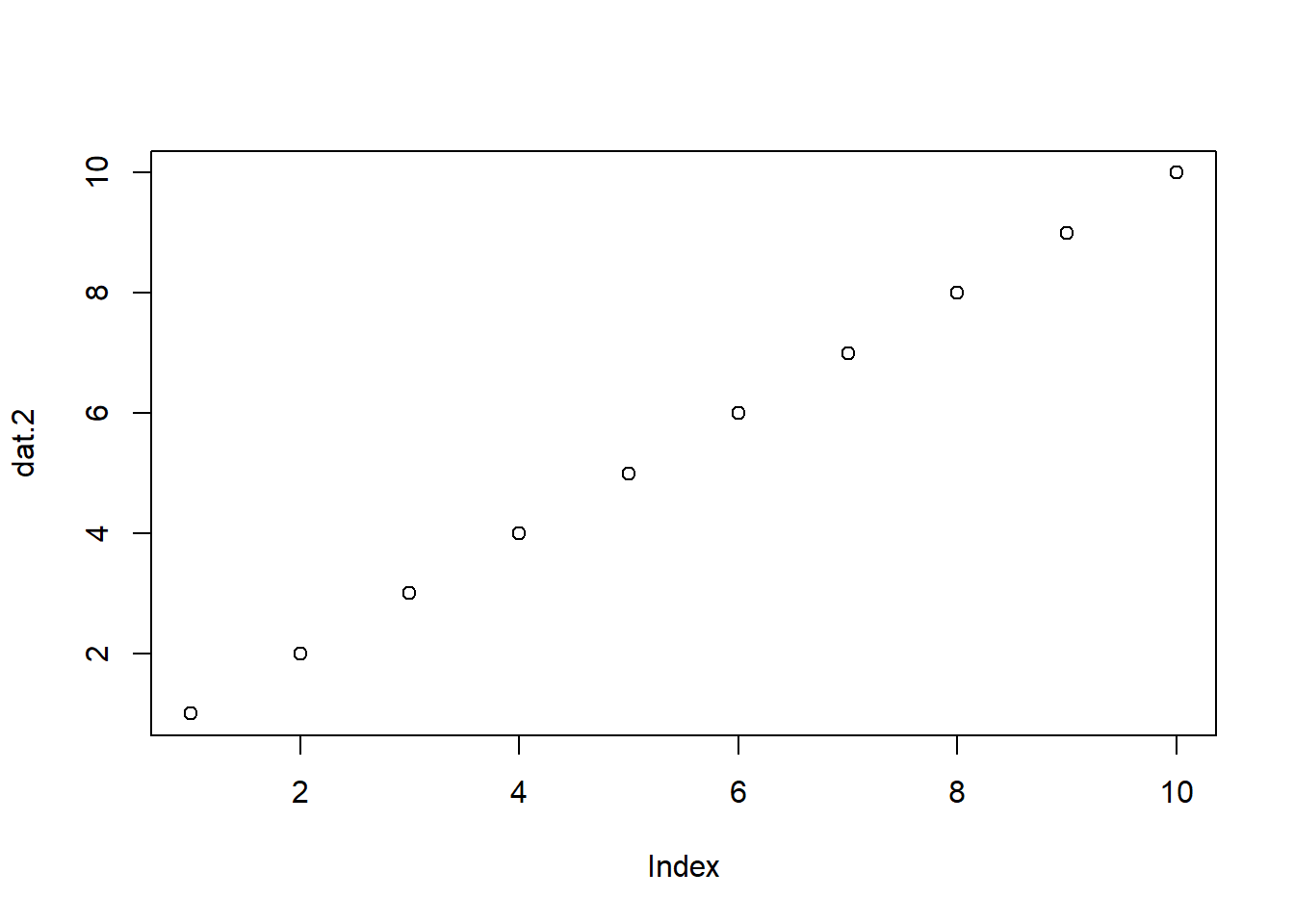
help(関数名)やウェブサイトで調べると、使い方を確認することができる。
3.9.1.4 ベクトル
データのまとまり
c()関数で作成可能。連続する数値であれば、:でもOK
numVector1 <- c(1, 35, 90, 0.9)
numVector2 <- c(1, 35, 90, 9)
chVector <- c("いちご", "strawberry", "イチゴ")
numchVector <- c("イチゴ", 1000, "みかん", "500")- 変数に何かを入れたら、必ず中身を確認する!
## [1] 1.0 35.0 90.0 0.9## [1] 1 35 90 9## [1] "いちご" "strawberry" "イチゴ"## [1] "イチゴ" "1000" "みかん" "500"- データの型がどうなっているかを確認。確認する関数は様々なものがある。[Environment]タブでも表示されている。
## [1] "numeric"## num [1:4] 1 35 90 9## [1] "character"## [1] "character"3.9.2 データを読み込む
研究では、ファイルに格納されたデータに対して分析を行う。データ基本的にxlsx、csv、txtという拡張子のファイルに格納されていることが多い(最近ではオンラインでのデータ収集によってJSON形式もよく見るようになりました)。
xlsx
- エクセルファイル。
csv (Comma-Separated Values)
- カンマ(,)で項目を区切ったファイル
txt
- 文字データだけが含まれるファイル(区切りは様々)
拡張子を表示させる設定に変更する。
データを読み込む場合、ファイルの種類によって読み込む際の関数が異なる。配布されたデータを、本講義用のR projectに移動させる( = 本講義用の📁)。
移動させたら、以下のコードを走らせ、データをR(Studio)に読み込む
- 文字化けしている場合教えてください。
以下の処理で、csvファイル内のデータを
datという変数の中に格納したことになる。
3.9.3 データフレーム
行(横)と列(縦)からなる、ベクトルのかたまり
- 数値、文字、因子など様々なベクトルを格納するデータ。データ分析のデータは基本的にこの型を指す。
読み込んだデータは基本的にデータフレームであるが、ベクトルから
data.frame()関数で作成することもできる。
- 数値は行の番号を指し、データには含まれない。
## name price
## 1 イチゴ 100
## 2 みかん 1503.9.4 要約統計量の算出
3.9.4.1 各統計量ごと
## [1] 642.9## [1] 20.09062## [1] 19.2## [1] 33.9## [1] 10.4## [1] 36.3241## [1] 6.026948## [1] 23.5# 尖度 (kurtosis) ※"moments" パッケージを使用
#install.packages("moments") # 初回のみ
library(moments)
kurtosis(mtcars$mpg)## [1] 2.799467## [1] 7.3753.9.4.2 一度に出力
base関数
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 10.40 15.43 19.20 20.09 22.80 33.90psychパッケージのdescribe関数
##
## Attaching package: 'psych'## The following objects are masked from 'package:ggplot2':
##
## %+%, alpha## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 32 20.09 6.03 19.2 19.7 5.41 10.4 33.9 23.5 0.61 -0.37 1.073.9.5 作図
Rに最初から登録されているデータセットを使用
描画のパラメータ。詳しくはウェブサイトを参考に(例 )
- main: 図のタイトル
- xlab: x軸のタイトル
- ylab: y軸のタイトル
- border: ヒストグラムの棒の枠線
- type: 線や点のスタイル
- col: 色を指定(e.g., “blue”, “red”, “green”)
- pch: 点の形指定(e.g., pch = 16 は●、pch = 17 は▲)
- lwd: 線の太さを指定
3.9.5.1 ヒストグラム
hist(mtcars$mpg,
main = "Histogram of Miles Per Gallon (mpg)",
xlab = "Miles Per Gallon",
col = "lightblue",
border = "black")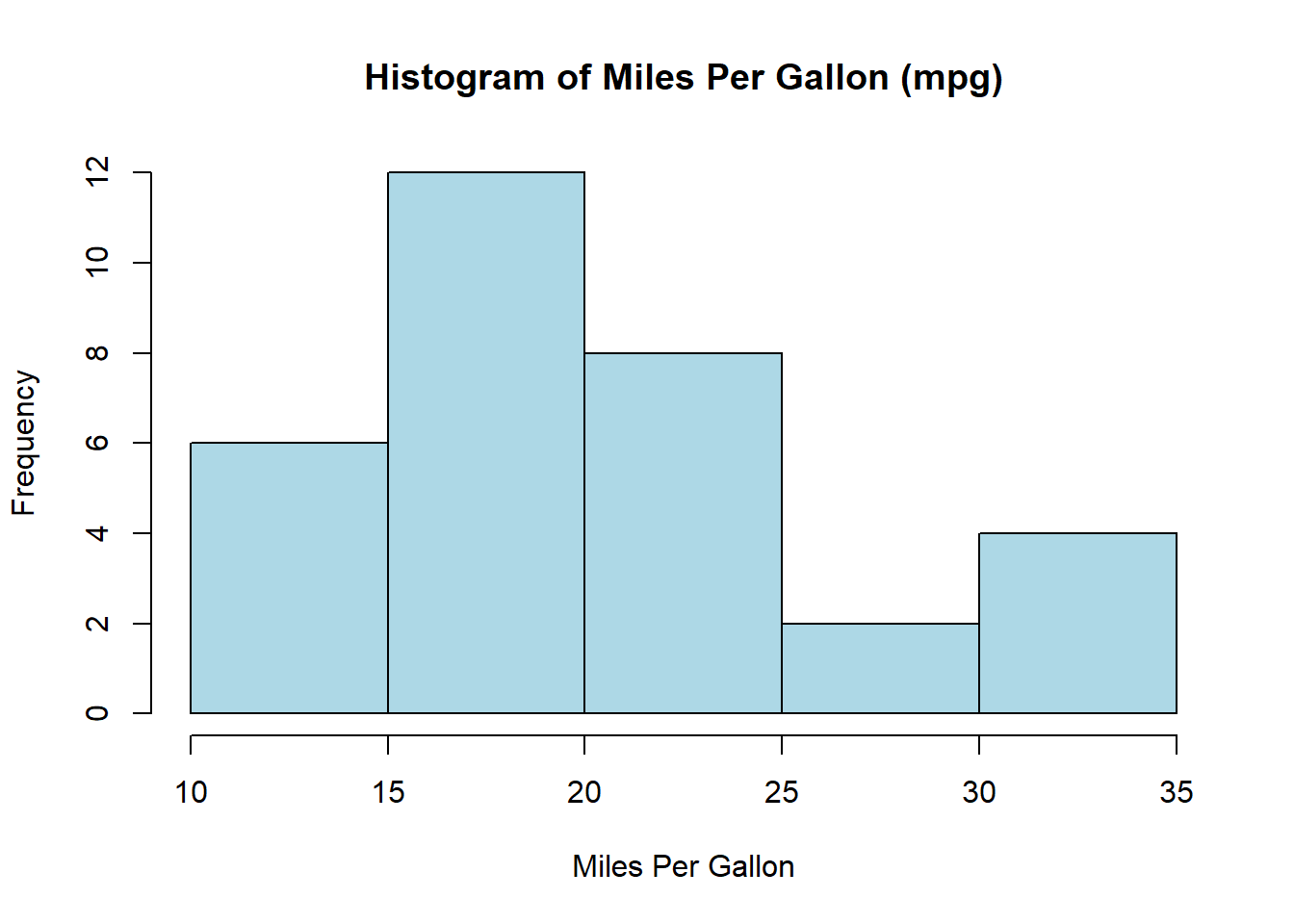
3.9.5.2 折れ線グラフ
plot(airquality$Temp,
type = "l",
main = "Daily Temperature in New York",
xlab = "Day",
ylab = "Temperature (°F)",
col = "blue",
lwd = 2)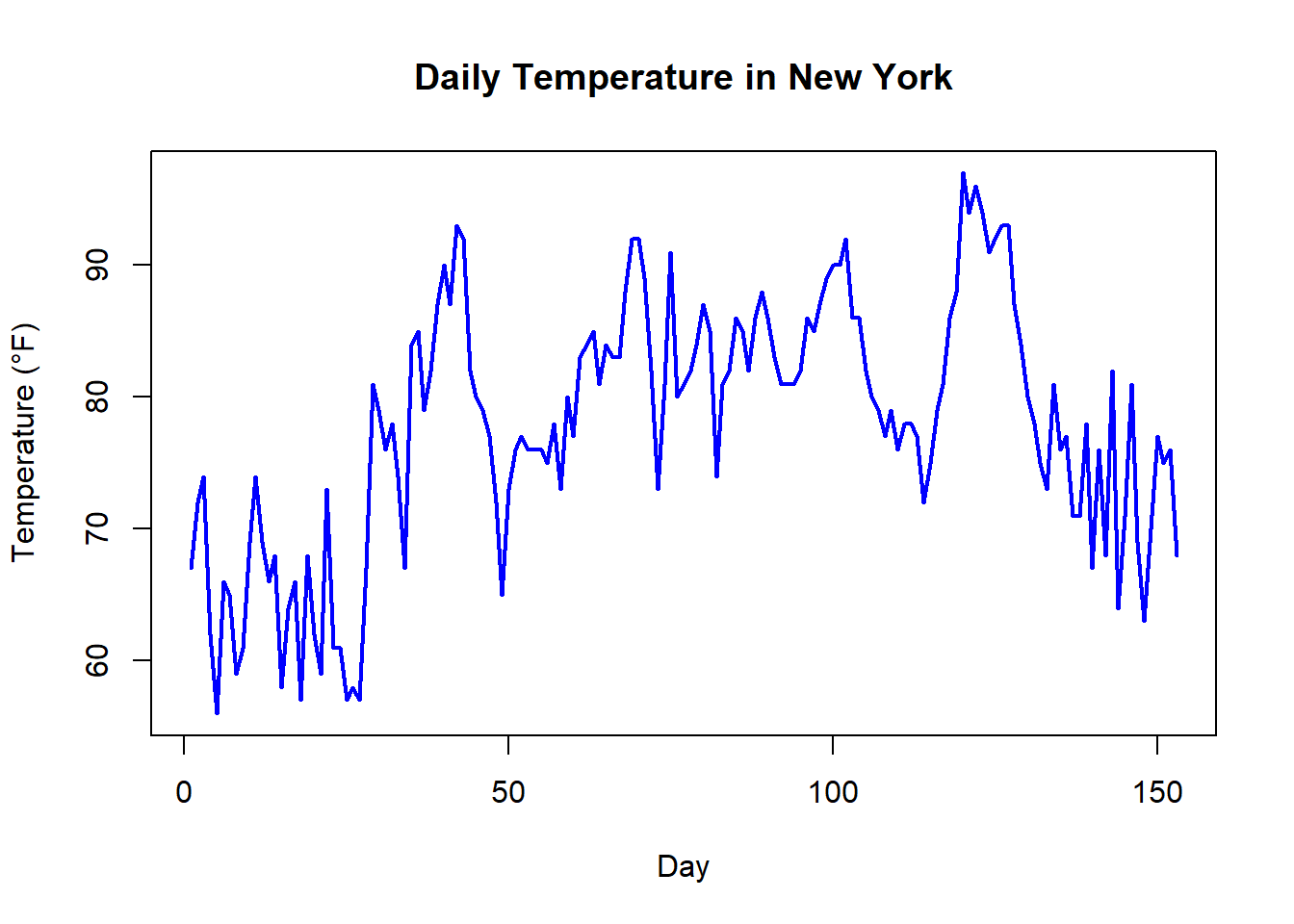
3.9.5.3 散布図
plot(mtcars$wt, mtcars$mpg,
main = "Scatter Plot of Car Weight vs. MPG",
xlab = "Weight (1000 lbs)",
ylab = "Miles Per Gallon",
col = "darkgreen",
pch = 16)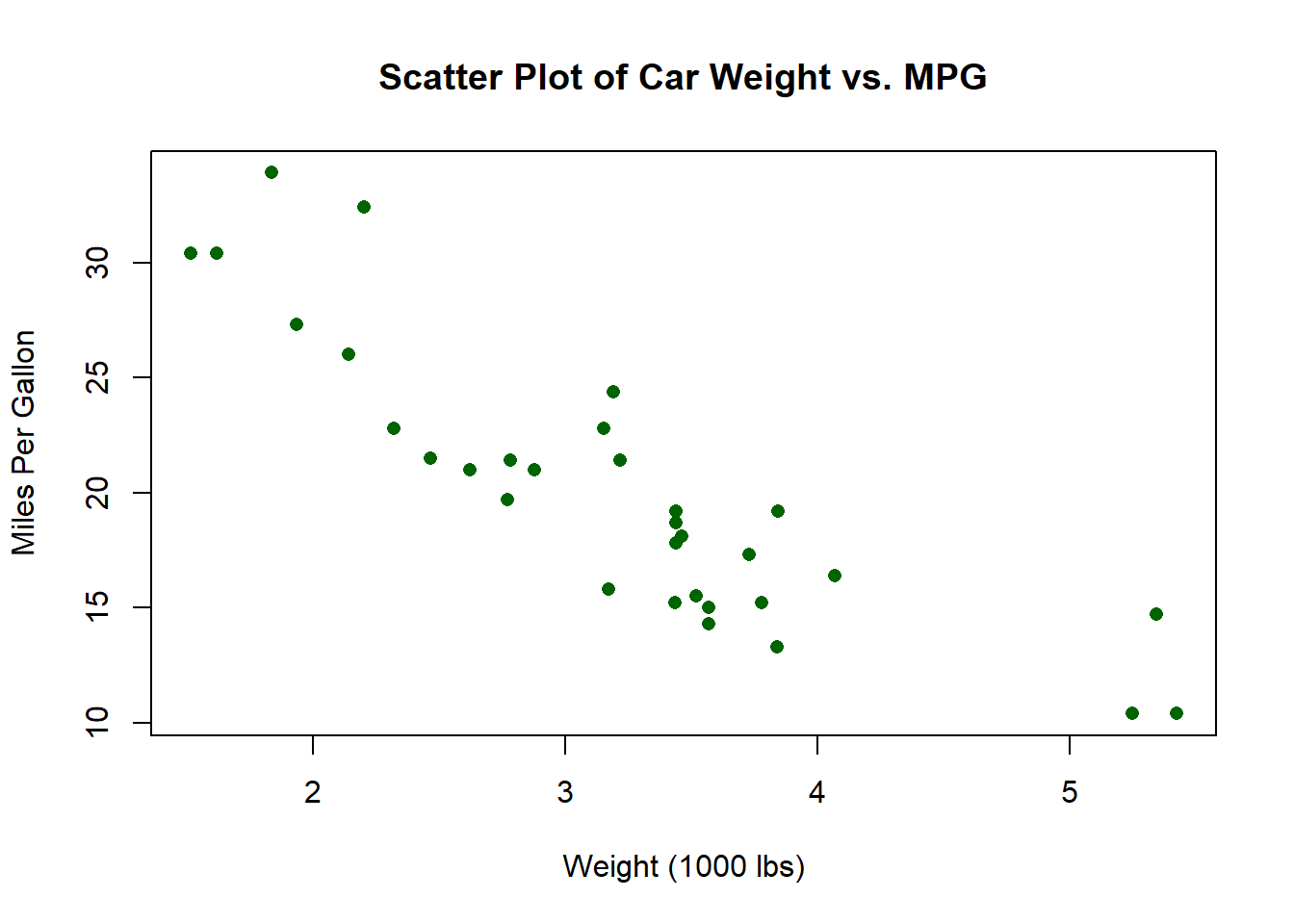
3.9.5.4 箱ひげ図
boxplot(mtcars$mpg[mtcars$vs == 1], mtcars$mpg[mtcars$vs == 0],
names = c("Engine: straight", "Engine: V-shaped"),
main = "Boxplots of Miles Per Gallon",
ylab = "Values",
col = c("lightcoral", "lightblue"))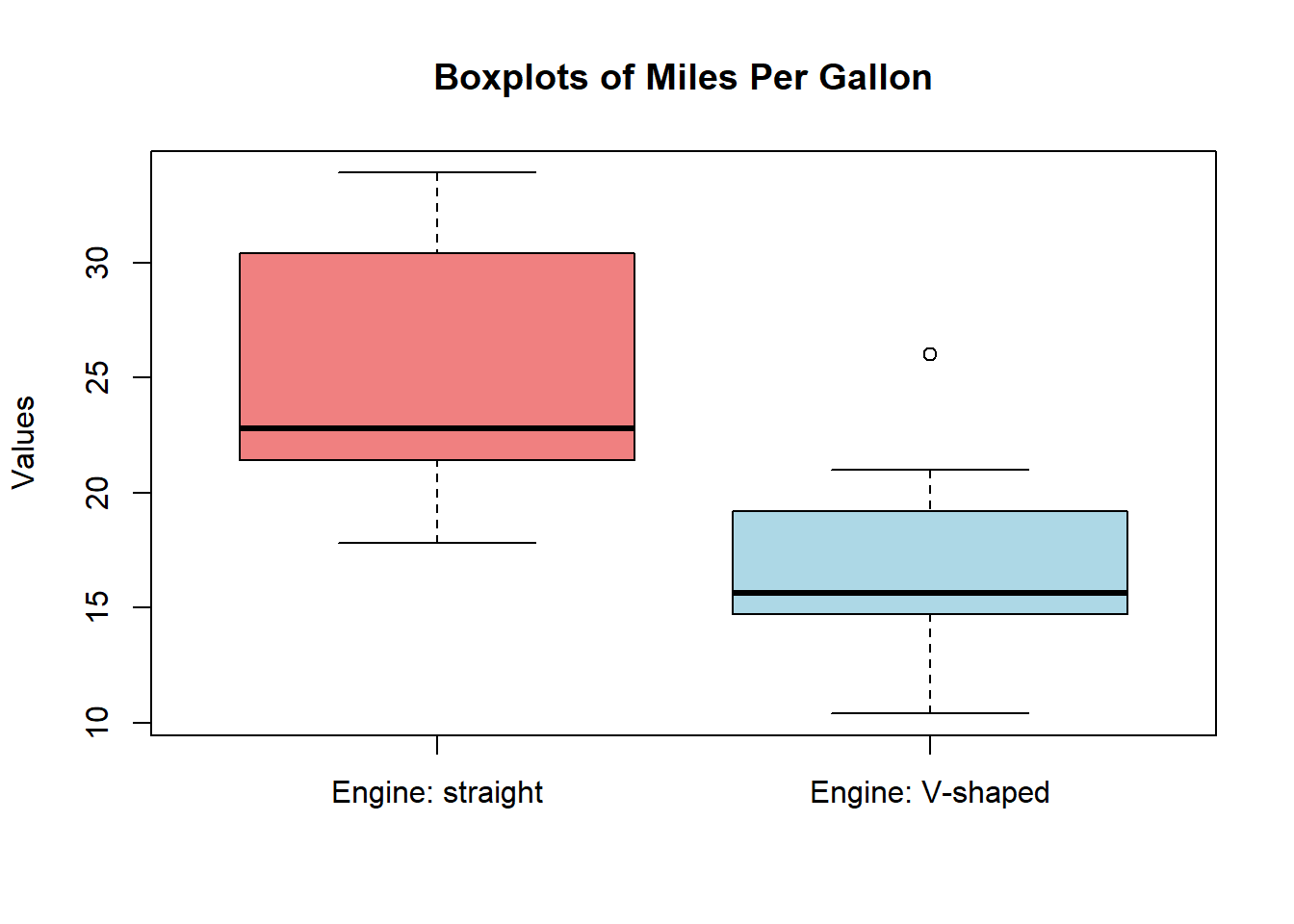
3.9.5.5 バイオリンプロット
## Warning: package 'vioplot' was built under R version 4.3.3## Loading required package: sm## Warning: package 'sm' was built under R version 4.3.3## Package 'sm', version 2.2-6.0: type help(sm) for summary information## Loading required package: zoo##
## Attaching package: 'zoo'## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numericvioplot(mtcars$mpg[mtcars$vs == 1], mtcars$mpg[mtcars$vs == 0],
drawRect = F, # Tにすると、箱ひげ図が中に描かれる
names = c("Engine: V-shaped", "Engine: straight"),
col = c("lightcoral", "lightblue"),
main = "Violin Plot of Miles Per Gallon",
ylab = "Miles Per Gallon")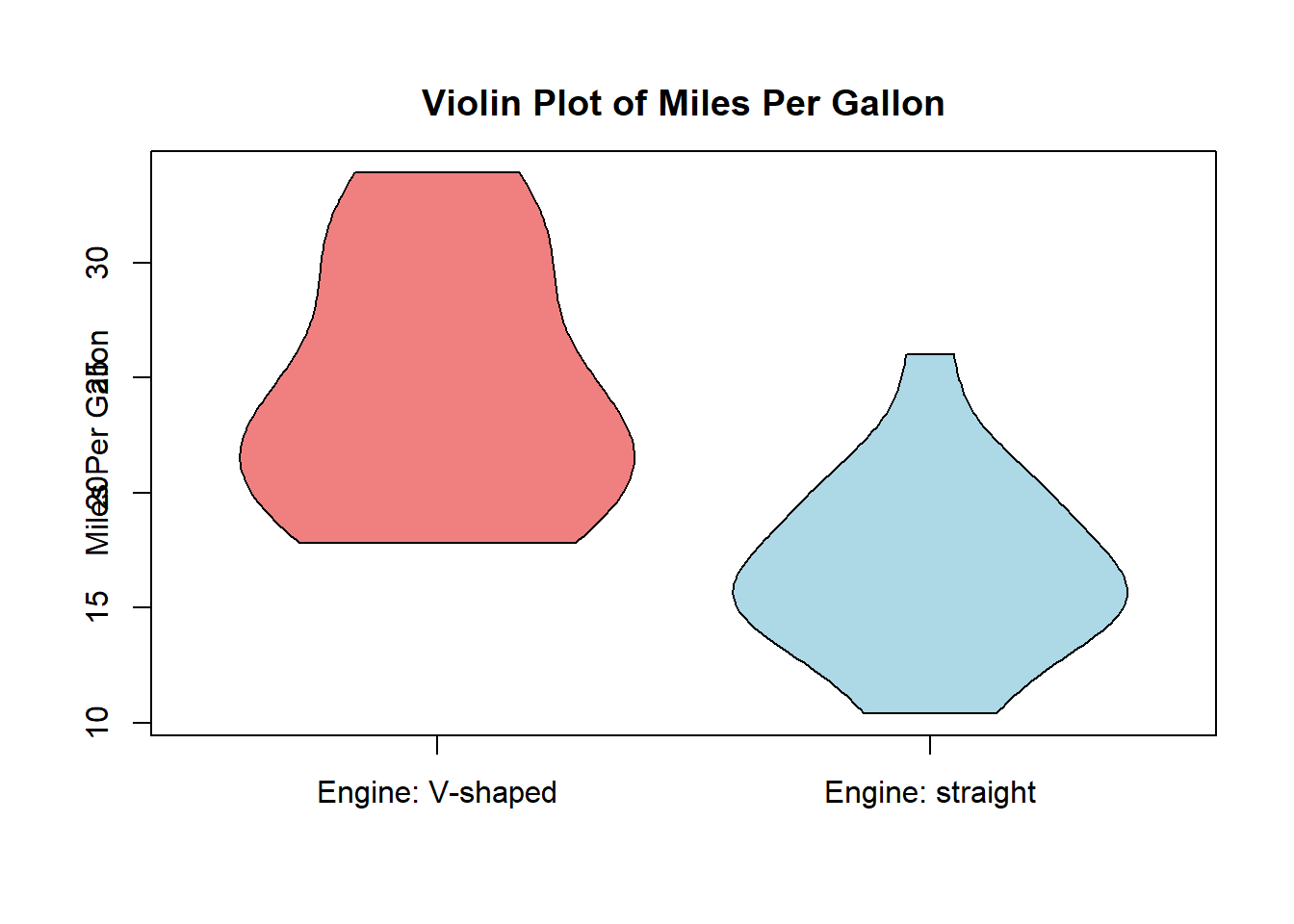
3.10 まとめ
(引用:平井 et al. (2021). 『教育・心理系研究のためのRによるデータ分析』 p. 3)
| 種類 | 指標 | 特徴 |
|---|---|---|
| 名義尺度以上 | 最頻値 (mode) | 最も多い度数を示すデータの値。主に名義尺度で用いられる代表値。 |
| 順序尺度以上 | 中央値 (median) | データを順番に並べたときの真ん中(50%タイル)の値。順序情報に基づくため外れ値の影響を受けにくい。 (例)テストの得点が {1, 3, 5, 7, 9} の場合は、中央値は 5 になる。 |
| 間隔尺度以上 | 平均 (mean) | 個々の測定値の和を測定値の個数で割った値。中央値に比べ、外れ値に引っ張られる傾向がある。なお、標本平均 \(\bar{x}\) と区別して母集団の平均を表す場合は平均(\(\mu\))と呼ぶ。 |
| 名義尺度以上 | 平均情報量 | 総度数と各カテゴリ度数との比率。 (例)本の貸し出し総数が 10 件とすると、総度数は 10 件。そのうち、フィクションは 3 件、実務書 3 件、ノンフィクション 2 件、それ以外のジャンルは 2 件とカテゴリ度数を示す。 |
| 順序尺度以上 | 範囲 (range) | 最大値と最小値との差。 |
| 順序尺度以上 | 四分位偏差 (quartile deviation) | 順に並んだデータを 4 等分し、その境界となる第1四分位数(\(Q_1\):25%タイル)と第3四分位数(\(Q_3\):75%タイル)の差を四分位範囲(inter quartile range)と言う。それを 2 で割った値が四分位偏差。 \(Q = \frac{Q_3 - Q_1}{2}\) |
| 間隔尺度以上 | 分散 (variance) | 平均からの偏差平方和の大きさを示す。データ \(x_i\) と平均(\(\bar{x}\))の差を2乗して、全データ(\(n\))またはデータ数 \(n-1\)(標本分散)で割った値。統計では、不偏不分散(unbiased variance)として、\(n-1\) で割ることが多い。 \(s^2 = \frac{\sum (x_i - \bar{x})^2}{n-1}\) |
| 間隔尺度以上 | 標準偏差 (standard deviation) | 上記の分散の平方根を取った値で、非負値になる。単位が元の値と同じ尺度なので直感的に解釈しやすい。小さい値はデータが平均の近くにあり、個別データのばらつきが小さいことを示す。 \(s = \sqrt{\frac{\sum (x_i - \bar{x})^2}{n-1}}\) |
3.11 次週までの課題
3.11.1 課題内容
小テストに向けて今回の内容を復習する。必ず手でコードを入力してRを実行する。
下記のデータをもとに、どの指標でもよいので、以下の内容を含めること。
要約統計量を算出
最低2つの図
気づいたことを2行以上でまとめる
ポケモンのデータセット(入手元)
- 一部列を削除している。
データの内訳
- id: 各ポケモンに振られた数値
- 名前:ポケモンの名前
- タイプ1:ポケモンに設定されている属性のようなもの。複数のタイプを持つポケモンがいるので、タイプ1となっている
- 高さ:身長
- 重さ:体重
- 世代:ポケモンには1~8まで世代が存在し、新しいゲームが出るたびに新種のポケモンが発表される
- ステータス:ポケモンが持つ6つ能力(HP、こうげき、ぼうぎょ、とくこう、とくぼう、すばやさ)の合算値
- HP: Hit Pointで体力のこと
- こうげき:物理技の攻撃力
- ぼうぎょ:物理技の防御力
- とくこう:特殊技の攻撃力
- とくぼう:特殊技の防御力
- すばやさ:どれくらい速くワザを出せるか
- 捕まえやすさ:数値が上がるほど捕まえやすくなり最大で255で、最小は3
- 進化:0 = 進化しないポケモン、1 = たねポケモン、2 = 1進化したポケモン、3 = 2進化したポケモン
- 画像URL:コピー&ペーストすればどんなポケモンか見れる
3.12 参考文献
- 📚清水(編著)(2021)『心理学統計法 (放送大学教材 1638)』放送大学教育振興会
- 📚竹内・水本(編著)(2023)『外国語教育研究ハンドブック【増補版】―研究手法のより良い理解のために』松柏社
- 📚西田(2022)『Rでらくらくデータ分析入門 ―効率的なデータ加工のための基礎知識』技術評論社
- 📚平井・岡・草薙(編著)(2022) 『教育・心理系研究のためのRによるデータ分析―論文作成への理論と実践集』東京図書
- 💻A Complete Guide to the Built-in Datasets in R
- 💻グラフのパラメータ
- 💻ポケモンで学ぶデータ分析|データの中身を知ろう